Proseguiamo con le
trasformazioni, ormai mancano pochi post

. Poi passeremo alla versione 2008 per capire anche come cambiano i componenti. Come abbiamo già visto in
questo post il Lookup component ha migliorato di molto la gestione della cache e del match. Alcuni componenti rimarranno simili ai predecessori, ma in linea di massima, essendo SSIS 2005 un prodotto riscritto interamente, troveremo tante migliorie e comodità in più.
Ma torniamo a noi. Parleremo di due semplici trasformazioni, il
Sort Transformation e l'
Aggregation Transformation.
Sort Transformation
Come già il nome indica il sort è un componente in grado di ordinare i dati. Riceve quindi in input un resultset e lo restituisce ordinato in base ai criteri definiti al suo interno. In base all'ordine con cui sono state selezionate le colonne viene effettuato l'ordinamento. Se si selezionano tre colonne, l'ordinamente viene effettuato prima per la prima selezionata, poi per la seconda ed infine per la terza. Inoltre vi è una funzionalità alternativa che permette di rimuovere le righe duplicate in base alle colonne selezionate per l'ordinamento. Questo componente risulta molto utile quando è necessario eseguire una Merge Join (ne parleremo nei prossimi post). Quest'ultimo infatti, si aspetta in input resultset ordinati. Prendiamo il seguente esempio:
ScenarioDue server di natura differente SRV01 e SRV02. Nel primo ho un'anagrafica di
utenti, nel secondo ho i
dettagli dell'utente che non sono gestiti nelle applicazioni del primo server. Ho la necessità di collegare gli utenti con i relativi dettagli per poter scrivere su di una tabella presente su SRV01. Immaginiamo un dataflow simile a questo:
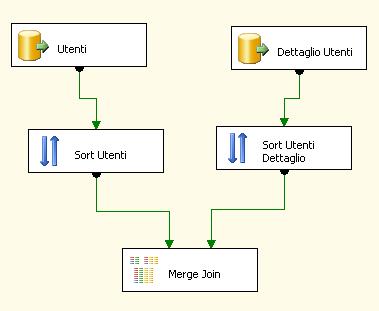
Siccome dobbiamo legare le due sorgenti provenienti da server differenti, possiamo utilizzare il task Merge Join. Rimuovendo il sort si ottiene un errore restituito dal package a design time:
"The IsSorted Property must be set to true on both sources of this transformation"
Anche aggiungendo l'order by nel comando sorgente il problema rimane. Il sort transformation risolve questo problema. A dire il vero, questo non è l'unico metodo.
In
questo tip infatti vi è la procedura per impostare la proprietà IsSorted a True. Dategli una letta

Abbiamo visto che il sort ordina i resultset. Ora vediamo com'è nel dettaglio:
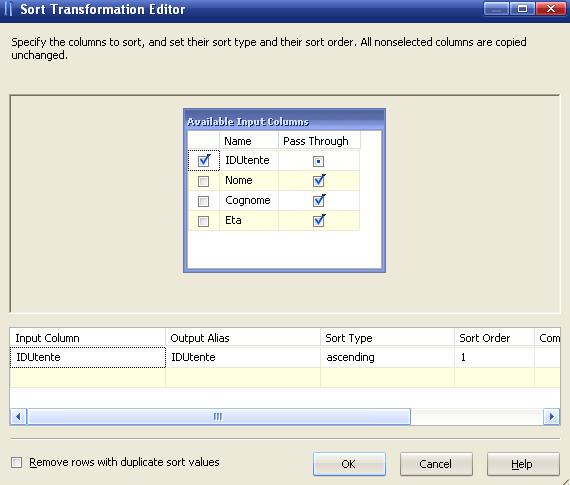
E molto semplice ed intuitivo, ha una sola form tramite la quale è possibile selezionare tre opzioni. Il primo flag a sinistra seleziona la colonna o le colonne che devono essere ordinate. Il secondo flag, denominato
Pass Through serve per determinare se "
inoltrare" la colonna nell'output. Quando il checkbox è deselezionato, l'output non possiede la colonna relativa.
L'ultima opzione, di fianco ai tasti di conferma, permette di eseguire la distinct sulle colonne selezionate, rimuovendo i duplicati in base alle colonne scelte per l'ordinamento.
Come la maggior parte dei task, anche il Sort ha un "Advanced Editor", raggiungibile premendo il tasto destro sul componente.
Qui troverete tutte le opzioni, comprese quelle che nei designer non vengono proposte.
Aggregate Transformation
Il task si occupa di aggregare i dati. Lo fa tramite funzioni di aggregazione come la AVG, o la SUM, oppure tramite semplici GROUP BY di dati. Può essere utilizzato in
Basic Mode oppure in
Advanced Mode. Nel primo caso possiamo definire trasformazioni a livello di colonna. Mentre nel secondo è possibile definre regole per il controllo della cache e delle prestazioni, nonchè la definizione di output multipli.
L'aggregation transformation è del tutto asincrono, quindi non esegue i raggruppamenti row-by-row, ma prepara una parte di aggragazioni creando le colonne in uscita, ragionando set based ed utilizzando una sua cache.
Ecco come appare in Basic Mode:
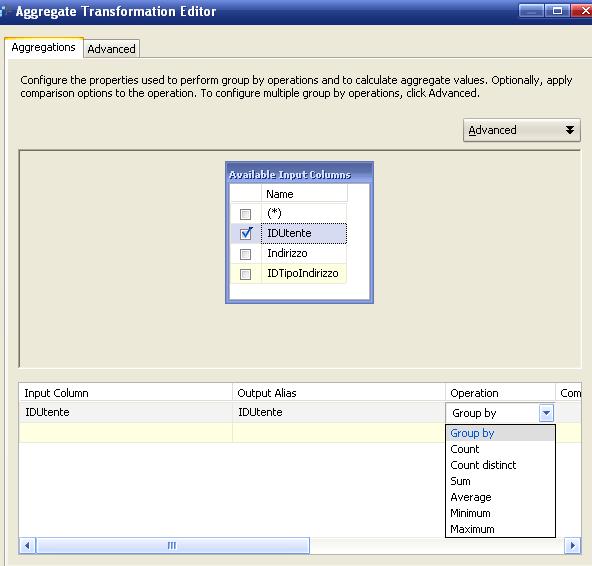
Quelle nell'immagine sono tutte le funzioni di aggregazione possibili. Ma non tutti i tipi dato possono disporre dell'intero insieme. Leggete
qui per capire quali funzioni sono disponibili in base al tipo di dato. Inoltre fate attenzione per alcuni tipi di dato numerici, dai BOL:
"
A column may contain numeric values that require special consideration because of their large value or precision requirements. The Aggregation transformation includes the IsBig property, which you can set on output columns to invoke special handling of big or high-precision numbers. If a column value may exceed 4 billion or a precision beyond a float data type is required, IsBig should be set to 1.Setting the IsBig property to 1 affects the output of the aggregation transformation in the following ways: * The DT_R8 data type is used instead of the DT_R4 data type. * Count results are stored as the DT_UI8 data type. * Distinct count results are stored as the DT_UI4 data type.Note:You cannot set IsBig to 1 on columns that are used in the GROUP BY, Maximum, or Minimum operations."
Per impostare la Proprietà
IsBig è necessario utilizzare l'advanced editor (tasto destro --> Advanced editor, sul task) e spostarsi sul tab "Input And Output". Selezionando una delle colonne di output che interessa la modifica è possibile impostare la proprietà.
Nel basic mode quindi, è sufficiente selezionare le colonne e definire la funzione di aggregazione. Avremo un output con gli aggregati.
In Advanced Mode invece, abbiamo quanto segue:
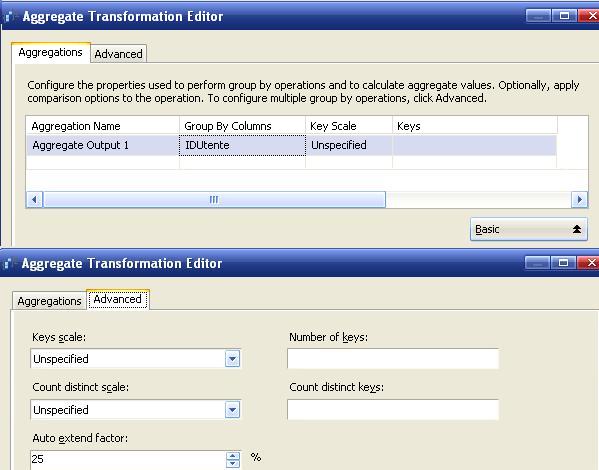
La sezione superiore indica la possibilità di definire più output per la trasformazione. Immaginiamo di voler tornare il numero dei dettagli per utente in un resultset e la semplice group by degli utenti in un altro. Con l'advanced mode è possibile creare resultset multipli definiti in maniera differente.
Spostandosi sul tab Advanced è possibile modificare le proprietà relative all'ottimizziazione delle performance.
Number of Keys consente di specificare il numero esatto di chiavi per la trasformazione.
KeysScale consente di specificare un numero di chiavi approssimativo.
Valorizzando
Number of Keys, la trasformazione non riscrive i dati nella cache, permettendo un buon miglioramento delle prestazioni.
Lo stesso discorso vale per le proprietà
CountDistinct solo che coinvolgono solamente le operazioni di quel tipo (COUNT DISTINCT).
Infine vi è la proprietà
Auto Extend factor, che determina la percentuale del'estensione della memoria utilizzata durante le operazioni di aggregazione.
Modificando opportunamente questi valori (ovviamente in base a quanto si conosce dell'operazione di aggregazione) è possibile gestire memoria e cache in modo tale da migliorare le prestazioni a runtime.
Abbiamo visto altri due task di trasformazione, nei prossimi post parleremo anche del precedentemente nominato Merge Join.
Stay tuned!
