Dopo aver parlato della parte riguardante il control flow, è arrivato il momento di spostarsi sul Data flow. Ma di cosa si tratta? Per capirci con chi conosce
DTS, è una sezione in cui vengono eseguite quelle che erano denominate trasformazioni e che venivano scritte direttamente sull’unico designer disponibile (le frecce nere). In generale si tratta di un’area in cui vengono scritte le logiche di caricamento, estrazione e trasformazione di dati ed in cui, generalmente, si passa da una o più sorgenti, a più logiche di gestione dei dati, a una o più destinazioni di ogni tipo.
Il task
DataFlow è presente nella toolbox del control flow. Trascinandolo nel designer non avremo altro che un task simile ad uno
ScriptTask o ad un
ExecuteSQLTask. L’unica vera differenza è che facendo un doppio click su di esso si apre un ulteriore designer dedicato solamente alle logiche di trasformazione dei dati.
Ecco come appare:
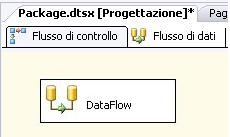
Come abbiamo detto prima, l’area dedicata al dataflow è suddivisa in tre parti:
- le
sorgenti (Sources) - le
trasformazioni (Transformations)- le
destinazioni (Destinations) Ognuna di esse è indicata nella toolbox:
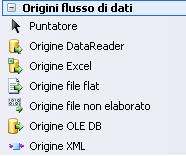
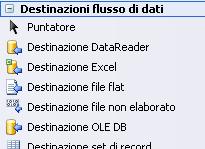

Nell’elenco non ci sono tutte, solo le sorgenti sono al completo.
Il dataflow, è molto versatile e molto potente. Però, come sempre, vi è un rovescio della medaglia. Quando scriviamo un dataflow e quando implementiamo tutte le logiche in esso contenute, utilizziamo dei
metadati. Per capirci, partendo ad esempio da un comando SQL SELECT, il task di sorgente che lo contiene torna in output un oggetto formato da tutti i campi definiti nello statement (
metadati). Ogni metadato in output è il corrispettivo campo della query, e l’oggetto che raggruppa questi metadati è disponibile come sorgente del nuovo task.
Una filosofia di questo genere è abbastanza rigida. Infatti basta un minimo cambiamento all’interno del flusso di trasformazione perchè tutti i collegamenti necessitino un aggiornamento. I motivi sono vari. Uno è che i metadati sono mappati agli statement tramite il loro nome e sono
CASE SENSITIVE. Quindi attenzione a minuscole e maiuscole!
Un altro è che ogni metadato possiede un ID numerico e quindi, ogni volta che lo stesso metadato si distrugge e si ricrea, gli viene assegnato un nuovo ID.
C’è anche da dire che Visual Studio ci viene in contro accorgendosi dei cambiamenti effettuati e andando ad aggiornare ricorsivamente tutti i task interessati dalla modifica. Ma a volte l’intervento manuale è necessario.
N.B. E’ possibile vedere quali sono i metadati passati da un task all’altro ed i loro tipi facendo un doppio click sui connettori (constraint) dei task, alla voce
Metadati (Metadata).
Detto questo passiamo a parlare dei dataflow sources, le sorgenti.
Abbiamo visto che sono molteplici. Per definirne un comportamento generale fornirò esempi solo su tre fra i più usati:
- OLEDB
- Flat File
- Script Ne esiste una ulteriore che appare molto importante ma che non ho indicato. La sorgente XML.
In un post successivo spiegherò perché evitarne l’utilizzo.
In questo post parlerò della
sorgente OLEDB.
Ricordiamo che sul designer di data flow si lavora esattamente come su quello di control flow, utilizzando drag&drop e doppi click.
Una volta aggiunto un dataflow sul control flow, facciamo doppio click su di esso e trasciniamo una sorgente sul nuovo stage:
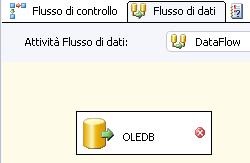
Notare che ora siamo nella sezione Flusso di dati (Data Flow) e non più sulla Flusso di controllo (Control Flow). Già da quest’area è possibile selezionare su che data flow ci si vuole spostare. Il tutto tramite la combobox alla voce “
Attività flusso dati:”.
Inizialmente il task compare con un segnalino di errore. Questo perché ogni sorgente (eccetto lo ScriptTransformationTask) necessita di un Connection manager (
post sui connection manager).
Ammettiamo di avere già un connection manager che punta al database di AdventureWorks.
Facciamo doppio click sulla sorgente:
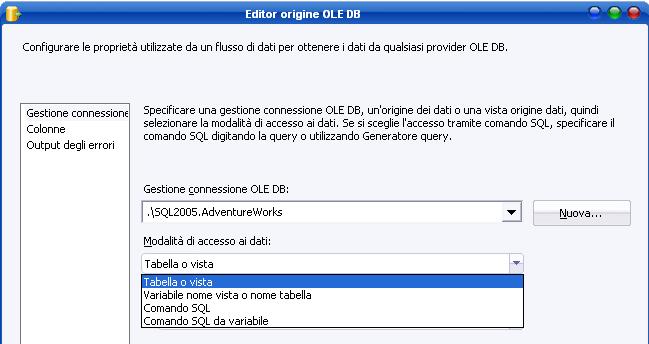
La prima proprietà da impostare è il connection manager di riferimento (nell’esempio c’è la connessione ad AdventureWorks). In secondo luogo vi è da definire la modalità di accesso ai dati, da scegliere fra:
-
Tabella o vista (table or view), ovvero una tabella o una vista definita sul DBMS
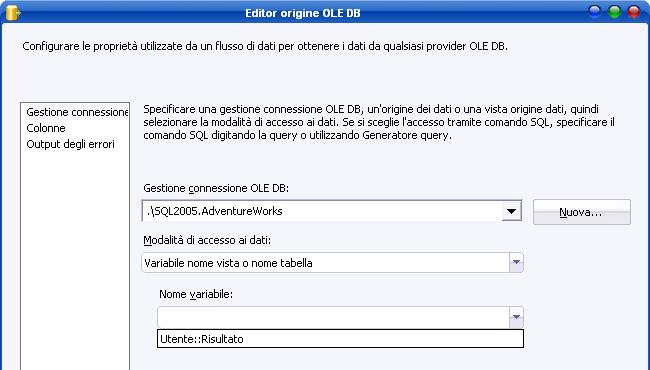
-
Variabile nome vista o nome tabella (table or view from variable), ovvero una variabile contenente il nome della tabella o della vista
-
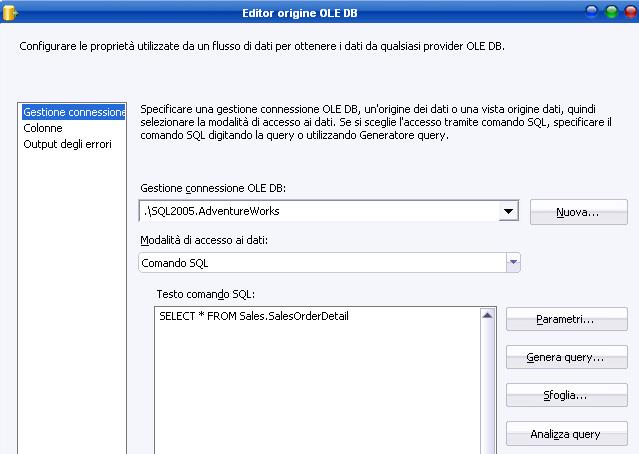
Comando SQL (SQL Command), ovvero un comando T-SQL
-
Comando SQL da variabile (SQL Command from Variable), ovvero una variabile che contiene il comando SQL per la sorgente.
Nel primo, nel secondo e nel quarto caso, sotto la combobox della modalità di accesso ai dati, ne comparirà una ulteriore per la selezione della tabella/vista o della variabile:
Nel terzo caso si aprirà l’editor testuale per la scrittura del T-SQL.
Una volta definiti i parametri per il connection manager ci si sposta sulla sezione
Colonne (Columns) in alto a sinistra.
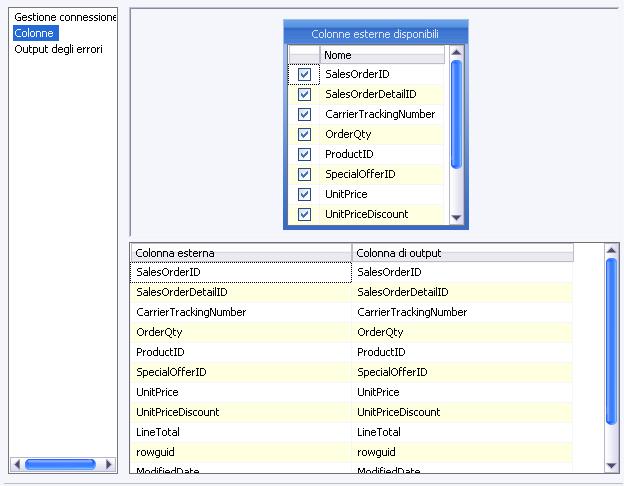
In questa sezione si configurano i metadati di output, partendo dalla sorgente che abbiamo selezionato in precedenza. Nell’ultima figura ho evidenziato le colonne relative allo statement SQL “
SELECT * FROM Sales.SalesOrderDetail”. Come si può notare SSIS propone già la colonna di output con il medesimo nome di quella di input (quella esterna, indicata nello statement). Questi sono i metadati di cui parlavamo prima.
Nella tabellina in alto appare una colonna con checkbox tramite i quali è possibile eliminare una colonna per l’output. Questo è molto utile se la tabella/vista o la query che dobbiamo scrivere ha molti campi. Basta infatti scrivere una “
SELECT * FROM tabella” e deselezionare i campi che non si vogliono utilizzare in seguito.
È consigliabile utilizzare tutti i campi definiti nei metadati ed è consigliabile scrivere un SQL che contenga
solamente i campi che si utilizzeranno di seguito. Il motivo è semplice. A runtime, SSIS elabora lo statement e porta in cache, tramite i metadati definiti, il resultset corrispondente. Ne risulta che i campi che non sono in seguito utilizzati vengono considerati ugualmente, facendo calare non sempre di poco le prestazioni. Sono caricati in cache ma mai utilizzati.
Anche il log lo indica come warning, e ci consiglia di rimuovere le colonne indicate che non sono utilizzate nel flusso dati.
Vi è poi un’altra sezione importante, la gestione degli errori di output.
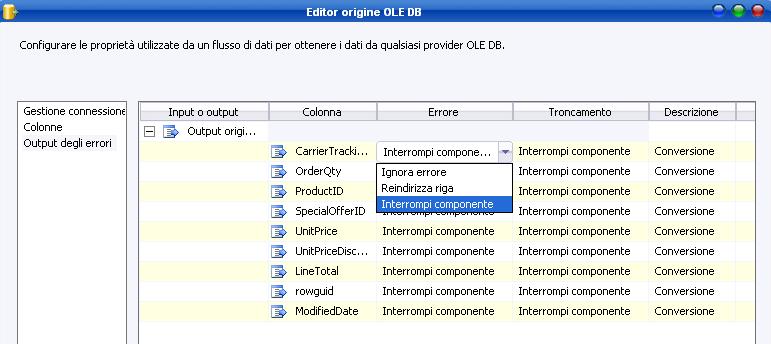
Tramite essa è possibile gestire gli errori che si possono presentare per ogni metadato ed eventualmente reindirizzare la riga verso una destinazione che li conterrà. Allo stesso modo è possibile interrompere il componente (comportamento di default) o ignorare l’errore.
Se il comportamento di default viene cambiato su “
reindirizza riga” sarà in seguito necessario collegare il constraint dell’errore (freccia rossa) verso un nuovo task.
Questo è il comportamento di una sorgente OLEDB su sql server. Per cambiare il tipo di DBMS è sufficiente cambiare il connection manager corrispondente al task source. Rimando al prossimo post per parlare delle altre due sorgenti molto importanti, lo script e il flat file.
Stay tuned!
