I container sono un’altra delle tante innovazioni di SSIS rispetto ai DTS di SQL Server 2000. Permettono di effettuare raggruppamenti logici di task, creare logiche complesse, ciclare su resultset (ado.net, ado, files, …) senza scrivere codice e migliorare la visualizzazione del pacchetto. L’utilizzo di questi contenitori, inoltre, permette di definire variabili con
scope differenti (e quindi anche con lo stesso nome, ma appartenenti a “padri” differenti), ognuno relativo all’oggetto in cui si trova. Altra possibilità che danno è la
drill/collapse, ovvero l’espansione del contenuto o la chiusura dello stesso all’interno del container, del quale rimane una breve descrizione, in modo che i task interni, seppure esistenti, occupino meno spazio.
I container possono essere inoltre nidificati, quindi potremo avere rappresentazioni con contenitori di altri contenitori, e via discorrendo. In questo modo si può capire la complessità delle logiche che possiamo scrivere col loro utilizzo.
Per aggiungere task ad uno qualsiasi dei container è sufficiente trascinare un task all’interno dell’area identificata nell’immagine di seguito:
Tutte le variabili del task trascinato, vengono portate anche nel contenitore, mantenendo il corretto scope.
I container esistono solo nel Control Flow e possono essere di quattro tipi:
Task Host container Il Task Host Container è il container di default nel quale ogni singolo task risiede. Non si vede da nessuna parte, nemmeno nella toolbox, ma viene creato ogni qual volta un task non risiede all’interno di un altro container.
Sequence container
Il Sequence container permette di raggruppare un sottoinsieme di task secondo logiche più semplici e gestibili. Oltre alla utile funzione di raggruppamento, questo container può gestire esecuzioni multiple di task e
transazioni sull’esecuzione degli stessi, impostando opportunamente le sue proprietà (di default la
TransactionOption è
supported). In questo modo, fino a che tutto il contenuto non è stato eseguito, il container impedisce il passaggio agli step successivi, aumentando quindi il controllo sul flusso di dati.
For Loop containerCome già il nome indica, questo è un contenitore che consente cicli con determinate condizioni ed incrementi, come se si scrivesse un semplice ciclo a codice. Eccone un semplice esempio:
Le proprietà del for loop container si impostano tramite il doppio click sulla sua intestazione. Come per tutti gli altri task, comparirà un’interfaccia grafica:
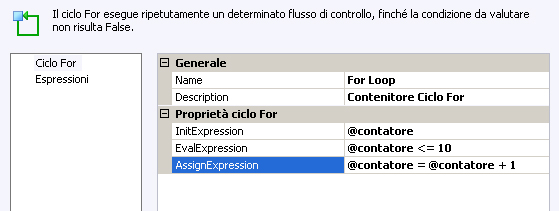
Con le proprietà
Name e
Description sarà possibile assegnare informazioni descrittive all’oggetto. Ma le proprietà di grande importanza sono:
-
InitExpression(opzionale), che inizializza il ciclo for
-
EvalExpression, che definisce la condizione tale per cui il ciclo prosegue o termina
-
AssignExpression(opzionale), che consente di definire un’espressione per cambiare la condizione del ciclo
L’altra finestra disponibile è quella delle expressions, di cui abbiamo parlato in un altro post precedente dal titolo
“Le Expressions” di “SSIS Basics”. Tramite essa è possibile impostare dinamicamente le proprietà del ciclo for.
Foreach Loop container
Questo container permette di creare un meccanismo di loop all’interno di una collezione, come un semplice for each scritto a codice. L’iterazione termina quando terminano gli oggetti nella collection.
Di seguito un semplice esempio:
Come con il for loop, per accedere alla finestra delle proprietà basta un doppio click sull’intestazione del container. La finestra che appare è simile alla precedente, costituita da una sezione
General tramite la quale è possibile impostare il nome e la descrizione del pacchetto. Ma le due finestre più importanti sono la
Collection(Insieme) e la
Variable Mappings(Mapping variabili), qui di seguito:
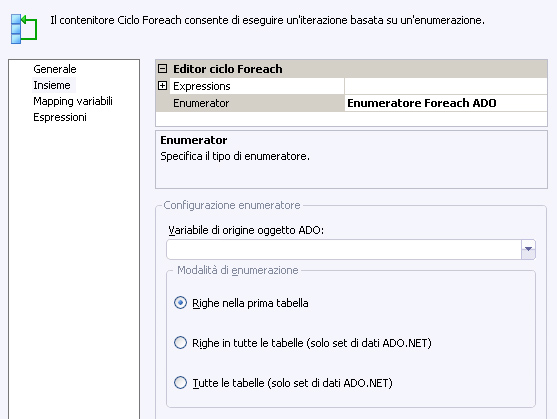
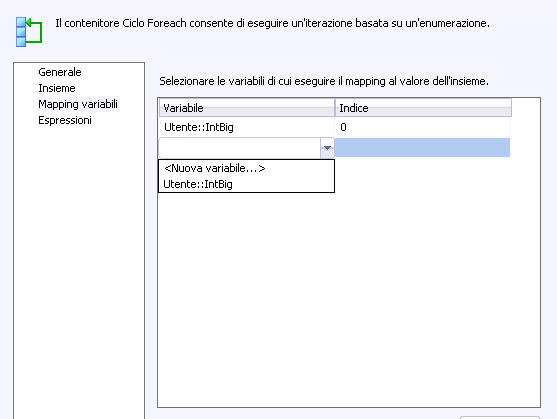
Tramite la prima finestra è possibile indicare quale enumeratore utilizzare, con la proprietà Enumerator. Ci sono sette tipi di enumeratori:
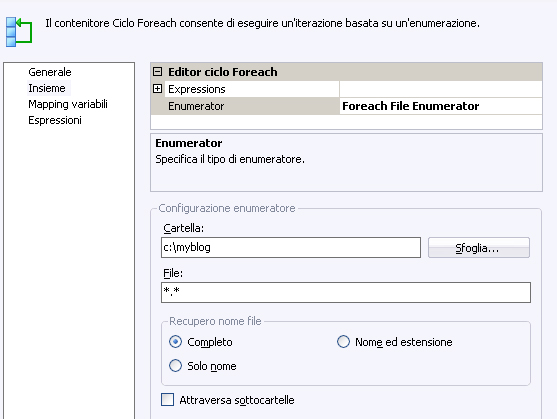
File Enumerator: ciclo per file con una determinata estensione contenuti in una cartella
Item Enumerator: ciclo per una lista di elementi impostati manualmente nel container
ADO Enumerator: ciclo su di una lista di tabelle o su righe di una tabella da un ADO recordset
ADO.NET Schema Rowset Enumerator: ciclo su un ADO.NET Schema
Da Variabile: ciclo su di una variabile SSIS
Nodelist Enumerator: ciclo su un elenco di nodi di un documento XML
SMO Enumerator: ciclo su di una lista di SQL Managements Objects
Per ognuno degli enumeratori selezionabili, l’interfaccia grafica sottostante ad essi varia. Ad esempio, se si sceglie un
File Enumerator sarà necessario impostare la cartella su cui ricercare, il pattern di ricerca (criterio) e il tipo di nome di file che si vuole ottenere (percorso esteso, nome e estensione, solo nome) nonché la condizione di ricerca ricorsiva nelle sottocartelle. Oppure, se si specifica un
ADO Enumerator, si dovrà impostare il resultset su cui ciclare (una SSIS variable) ed il tipo di resultset che si vuole ottenere (tutte le righe della prima tabella, le righe di più tabelle, tutte le tabelle).
Nell’esempio di seguito vogliamo ciclare su tutti i file contenuti nella cartella c:\myblog:
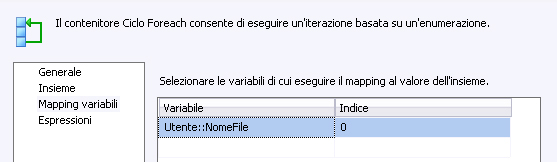
Nella finestra mapping variabili, in base alla selezione dell’enumeratore, dobbiamo assegnare i valori di ritorno alle SSIS variables. Prendendo l’esempio di prima, assegneremo il nome del file ad una variabile chiamata, ad esempio, NomeFile, in questo modo:
Selezionando l’enumeratore ADO, in base alla tipologia di resultset ritornato, cambia l’interpretazione del
Variable Mappings. Ad esempio, se si vogliono ottenere tutte le righe di una tabella, il mapping delle variabili corrisponderà all'associazione di ogni colonna della tabella ricavata ad una SSIS variabile. Se invece vogliamo ottenere più tabelle, ogni mapping corrisponderà ad una variabile object che conterrà la tabella stessa.
N.B. la colonna “index”(o indice) è zero-based, quindi il mapping con il primo elemento della collezione ha indice 0, la seconda 1, e così via.
Indicare sempre l’indice e mai il nome dell'eventuale campo.
Group box
L’ultimo tipo di grouping possibile è definito dal Group box. Si tratta di un container che non cambia l’esecuzione dei task, né tanto meno il loro comportamento. Esegue solamente un raggruppamento a design time, solo per delineare aree e rendere più leggibile il flow. Non esiste nella toolbox. È necessario selezionare i task di cui si vuole un raggruppamento, premere il dx del mouse su uno di essi e selezionare Group (o raggruppa).
Il group box è solamente un raggruppamento logico.Come gli altri containers, possiede le funzionalità di drill/collapse.
visibile:

invisibile:

E anche questo post termina qui, spero possa esservi di aiuto..
alla prossima!
