Ritorniamo alla nostra allungatissima lezione introduttiva su SSIS

, anche se alcuni di voi ormai avranno raggiunto uno skill talmente elevato da non dover nemmeno considerare questa pagina. Ma è il mio progetto iniziale e quindi lo porto a termine, cercando di coprire un po' tutti gli argomenti su Integration Service, perlomento quelli basilari
.
L'
ultima volta ci eravamo fermati alle
destinazioni dei DataFlow. In questo post cominceremo ad affrontare l'argomento più vario della sezione relativa al flusso dati, le
Trasformazioni.
Cosa sono? Generalizzando al massimo, mentre le sorgenti sono veri e propri "generatori" di dati e le destinazioni i "contenitori", tutto quello che sta nel mezzo è una trasformazione. Un dataflow può essere formato anche da una o più sorgenti che mappano una o più destinazioni solamente, ma in logiche complesse, i task di trasformazione sono necessari per portare le informazioni dallo stato A in cui si trovano alla sorgente, verso lo stato B necessario alla destinazione. Nella sigla
ETL, di cui SSIS rappresenta una delle implementazioni, le trasformazioni sono proprio la T (Extract, Transform and Load).
Per fare semplici esempi, pensate ad alcuni dati che arrivano denormalizzati su txt (in post precedenti, nella sezione
SSIS Tips abbiamo avuto modo di vedere già alcuni Dataflow con trasformazioni) e che devono essere portati su strutture più "normali" su sql server, access, excel. O viceversa, dati provenienti da vari
RDBMS che necessitano di essere scaricati su file flat, csv, xml, altre piattaforme.. e via discorrendo.
Le trasformazioni possono essere suddivise in quattro macrocategorie:
- Business Intelligence Transformations Permettono di implementare logiche di business sui dati (ad esempio
calcoli di Data Minig).
- Row Transformations
Consentono la creazione e l'aggiornamento di colonne in base alla riga passata in input al task (ad esempio Colonne derivate, Script component, Conversioni di date, Comandi OLEDB per riga)
- Rowset Transformations Consentono la creazione di set di dati aggregati, ordinati, trasposti (ad esempio il PIVOT/UNPIVOT, i task di raggruppamento, il task sort)
- Split and Join Transformations Consentono la distribuzione di un input in più output, l'unione di più input in un output oppure eseguono operazioni di lookup (multicast, union e lookup task)
Tutte le trasformazioni che non rientrano in questi quattro gruppi (ad esempio i RowCount, le Slowly Changing Dimension, ecc) sono stati categorizzati da Microsoft come
Other Transformations.
Ho deciso di saltare il primo gruppo, quello legato alla BI, soprattutto per frequenza di utilizzo nella maggior parte delle applicazioni in cui i SSIS vengono applicati. Vi lascio comunque la reference su MSDN qualora doveste averne bisogno. L'elenco dei task relativo a questa sezione è:
-
Fuzzy Grouping-
Fuzzy Lookup-
Term Extraction-
Term Lookup-
Data Mining QueryPassiamo quindi alle
Row transformations. L'elenco è il eguente e anche in questo caso lascio il link ad MSDN:
-
Character Map Transformation-
Copy Column Transformation-
Data Conversion Transformation-
Derived Column Transformation-
Script Component-
OLE DB Command Transformation Le tre maggiormente utilizzate nella mia esperienza da SSIS developer
sono state la
Derived Column, la
Data Conversion e lo
Script component.
Con la prima è infatti molto semplice modificare i metadati provenienti da una sorgente. Grazie a
Derived Column infatti è possibile aggiungere colonne, indicando un nuovo nome ed una espressione che riassume il valore che conterrà quel particolare campo.
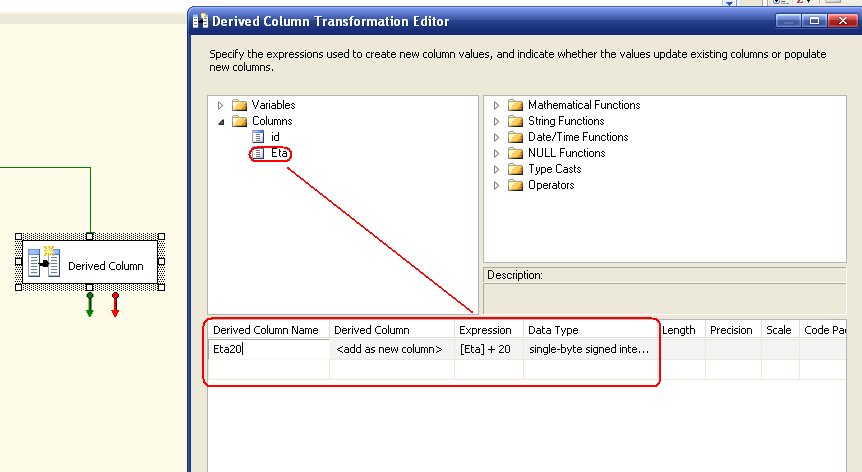
Facciamo un esempio. Supponiamo di avere una sorgente dati che ci passa un campo particolare, che deve essere sia elaborato, sia tenuto com'era in origine. Ad esempio, l'età di una persona e la sua età fra 20 anni (esempio semplificato al massimo, non è necessario un SSIS per questo "problema"

).
In questo contesto possiamo creare una colonna Eta20, derivandola da Eta ed aggiungendo un'espressione data dalla colonna Eta + 20:
Integration Services includes the following transformations to export
and import data, add audit information, count rows, and work with
slowly changing dimensions.
Possiamo notare come è semplice creare la colonna derivata, trascinando la colonna in input verso la sezione sottostante per creare la riga su cui fare il calcolo. La prima informazione da inserire è il nome della nuova colonna, il tipo di operazione, l'espressione ed il tipo di dato con le eventuali informazioni aggiuntive sul tipo stesso.
Come tipo di operazione (seconda colonna, Derived Column) è possibile aggiungere una o più nuove colonne, e allora si procede come nell'esempio, oppure sovrascriverne il contenuto. In questo caso l'esempio cambia leggermente. Il nome non è editabile, poichè rimane lo stesso della colonna sorgente, e il tipo di dato dell'espressione deve obbligatoriamente ritornare il tipo della colonna sorgente stessa. Alla fine dell'operazione avremo in output del task un numero di metadati in più tante quante sono le operazioni di <add as new column>.
E' possibile notarlo con un semplice doppio click sui constraints (le frecce):
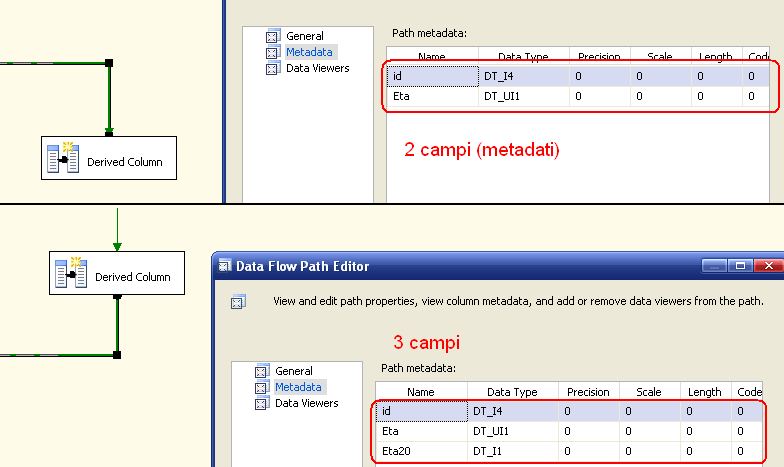
E' possibile inserire infatti più colonne derivate (nell'esempio solo una), anche solo per convertire il dato.
Tuttavia è consigliabile utilizzare l'altro task progettato proprio per le conversioni, il
Data Conversion. Anche questa trasformazione, riceve in input una row e processa i metadati, trasformandoli in nuovi metadati, agendo però solamente sul tipo di dato. Continuiamo col nostro dataflow. Immaginiamo di voler convertire il campo Eta20 da intero a 1byte (DT_I1) verso una stringa:
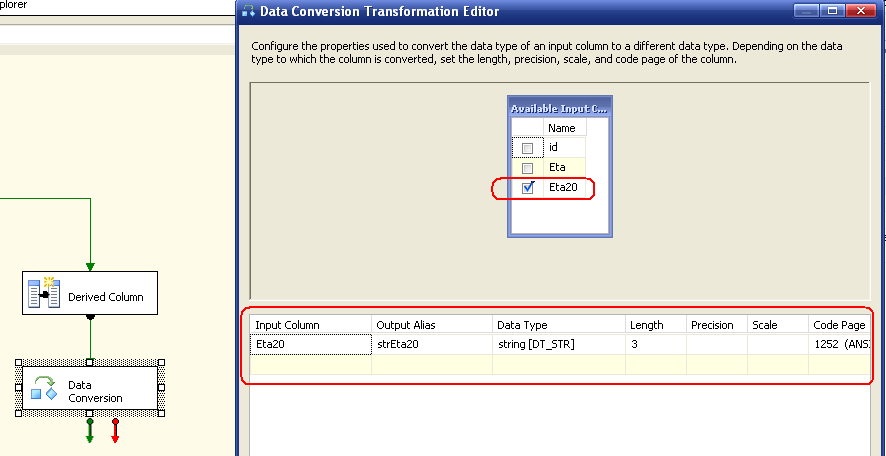
Si seleziona la colonna e si definisce la conversione. In questo caso, parto dalla colonna Eta20 e arrivo ad una nuova colonna strEta20, di tipo stringa con CodePage 1252 (ANSI Latin) e lunghezza 3 caratteri. Come per la derived column possiamo controllare l'input del task e l'output. Nel nostro caso in input ci sono le tre colonne di output del derived column task ed in output c'è la colonna strEta20 in più.
Seppure la trasformazione Copy Column sia comunque utilizzata, preferisco saltarla; noterete come si avvicina alla Data Conversion (molto più semplice di quest'ultima). Anche la OLEDB Command, che si discosta però da tutte le trasformazioni che stiamo affrontando, non verrà trattata in questo post. E' sufficiente sapere che esegue il comando riga per riga. Quindi prende la riga in input ed esegue un comando SQL. Attenzione a non abusarne, proprio per la sua logica ciclica. Mi è capitato di utilizzarla per gestire alcuni lookup errati, in modo da salvarli all'interno di tabelle di log. Può risultare utile anche per "appoggiare" i dati non validi al momento su di una tabella che viene controllata periodicamente al fine di cercare di ripristinare eventuali record.
Comunque sia vi ho consiglio di leggere la reference su MSDN.
Terminiamo in vece con la trasformazione più particolare, proprio perchè potrebbe anche non essere una vera e propria trasformazione. Lo
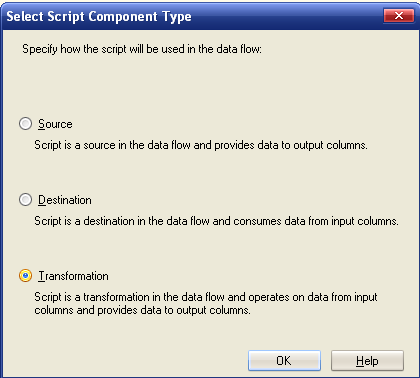
Script Component. Ogni qual volta esso viene trascinato sullo stage la prima richiesta è "come deve comportarsi?" e le possibili risposte sono "sorgente", "destinazione", "trasformazione". Il caso che ci interessa è proprio quest'ultimo.
Partiamo dal presupposto che anche questo task si comporta come le transformation di cui abbiamo parlato; ha un input (che porta con se metadati) e un output.
Quello che trasforma è la logica dello script, quindi quello che andiamo a scrivere noi. Si utilizza quando altri task non soddisfano le nostre richieste, ma come ho già detto
qui e
qui, può essere comodo anche per bypassare degli scomodi comportamenti di altri componenti.
Supponiamo, per comodità, di dover ripetere le funzioni definite dai due precedenti task. Partiamo da una tabella che ha il campo Eta e vogliamo arrivare a strEta20. Con lo script, come prima cosa si sceglie la natura del component:
Successivamente si selezionano gli input, ovvero i metadati derivandi dal task precedente:
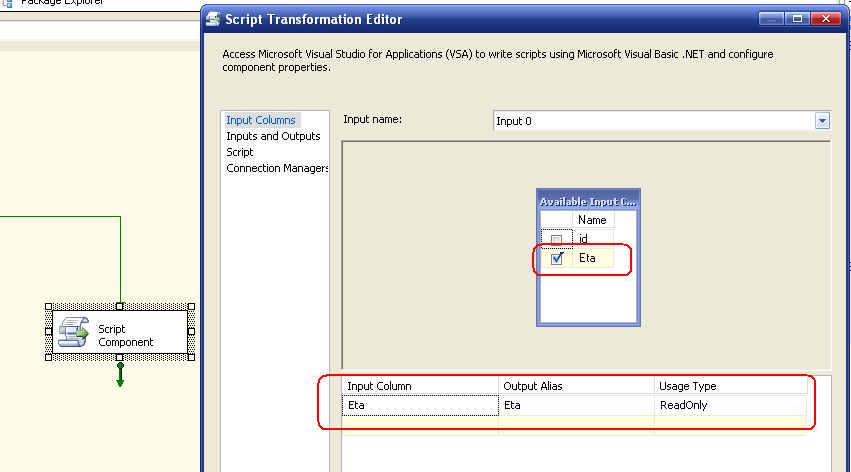
Da notare la colonna UsageType che determina se le colonne possono essere anche scritte, oltre che lette. La fase seguente consiste nel preparare l'output:
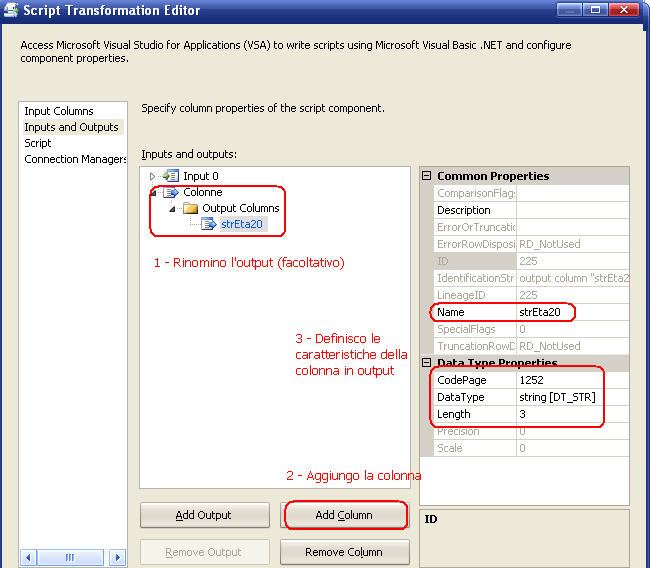
Si rinomina l'output (operazione facoltativa) poi si aggiungono tante colonne quante si vogliono aggiungere in output del task ed infine si definiscono i rispettivi parametri (tipo di dato, lunghezza, codepage, precisione, scala, ecc..). Infine si progetta lo script:
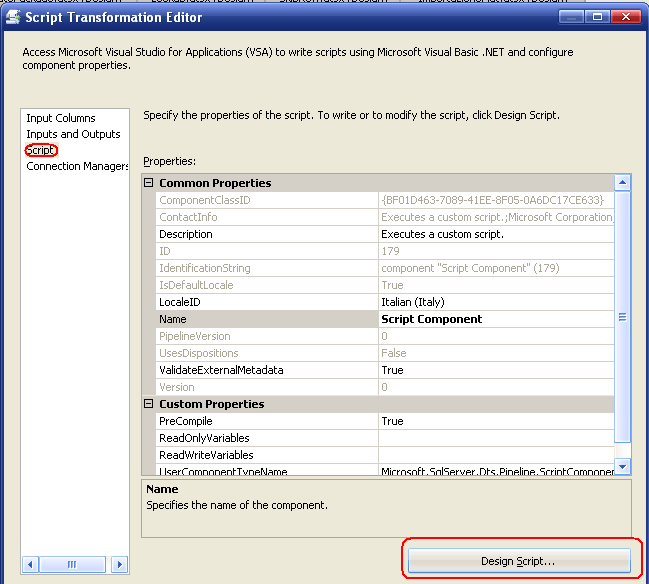
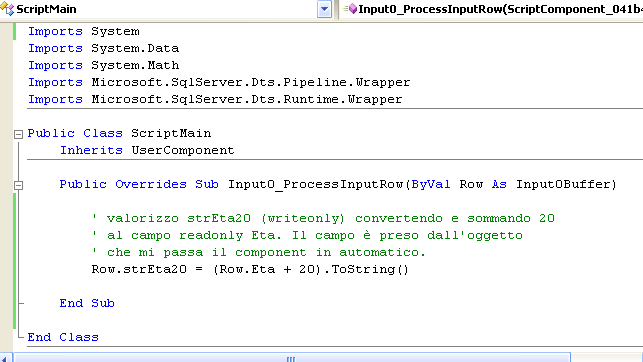
Il metodo già proposto da SSIS è Input0_ProcessInputRow tramite il quale è possibile usare l'oggetto Row, passato come parametro, come se fosse la riga corrente. Ed è proprio in questo metodo che ho scritto la somma e la conversione. Vi sono poi altri metodi su cui è possibile agire:
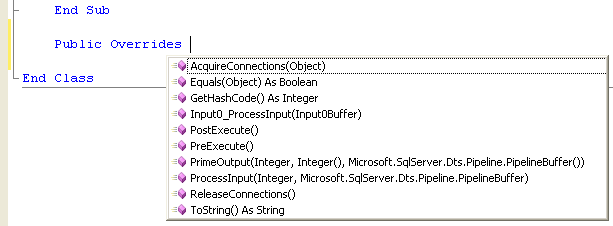
Per questi leggete questo
link relativo ai metodi dello script component.
Mi fermo qui nell'introdurre le trasformazioni. Dobbiamo affrontare ancora due gruppi, e nei prossimi post vedremo come comportarci con le possibilità che Integration Services ci fornisce.
Vedendo una prima carrellata, è normale pensare che lo script potrebbe risolvere molti dei vostri problemi, comunque sia, vi consiglio di capire e conoscere bene gli strumenti e le altre funzionalità che il resto dei task possono darvi. Questo per comprendere se il codice scritto da voi (noi, mi ci metto anche io

) può darvi veramente dei vantaggi.
Ricordatevi che l'architettura di SSIS è ottimizzata ed è in grado di parallelizzare le operazioni (nonchè gestire la memoria in maniera molto intelligente). Quindi fate prima attenzione a tutto quello che potete provare prima di arrivare a scrivere "vagonate" di codice.
Stay tuned!
