Abbiamo già accennato in questo
post l'utilizzo del Conditional Split transform per saltare le righe in un determinato flusso di input. Le principali caratteristiche sono quindi già state evidenziate, e sono:
- In quanto trasformazione, sta all'interno di un dataflow e non può essere il primo task della trasformazione stessa.
- In quanto trasformazione, possiede un input ed n output (uno per condizione creata più uno per la condizione di default)
- In input riceve quello che arriva da un task precedente e lo gestisce in base alle condizioni create
- Possiamo indicare nelle espressioni di condizione sia variabili che colonne
In aggiunta ad esse vi è l'advanced editor anche se le proprietà avanzate non sono molto importanti. Diciamo che l'editor di default è più che sufficiente per configurare il componente al meglio.
Solo un'opzione, la
ValidateExternalMetadata, può esserci di aiuto nell'editor avanzato. Essa serve infatti per decidere se validare i metadati esterni al componente a design time:
IDTSComponentMetaData90.ValidateExternalMetadata PropertyPuò essere utile, ad esempio, se le condizioni del componente sono create a runtime e quindi per quelle condizioni i cui metadatai ancora non esistono. Lasciando a true la proprietà
ValidateExternalMetadata in un caso come questo, otterremmo un errore in fase di design, il che impedirebbe il corretto caricamento del pacchetto in fase di editing e, a volte, anche di esecuzione. Ricordiamo che questa proprietà non è riservata al task Conditional Split, bensì a tutti i task di trasformazione di SSIS (tutti i task di un dataflow).
Per dare una ulteriore overview del task, vediamo come esso può risultare utile per la gestione dei NULL.
ScenarioPartendo da un foglio excel contenente i contatti di una rubrica, dobbiamo caricare questi dati su SQL Server 2005. Il campo email sul foglio excel può essere non riempito ma su SQL Server non è consentito l'inserimento di NULL. Se la email risulta mancante, si dovrà inserire su sql server il valore stringa "N/A".
Ecco come procedere:
1) creare un connection manager per i contatti
2) creare un dataflow che conterrà la trasformazione
3) aggiungere una sorgente Excel e definire il record
4) legare all'output della sorgente il conditional split per gestire i NULL
5) mettere unione i dati non NULL con quelli NULL gestiti dal conditional split
6) inserire su tabella SQL Server
1) Per creare il connection manager dobbiamo aggiungerne uno non presente nel menu rapido. Dovremo utilizzare
New Connection..:
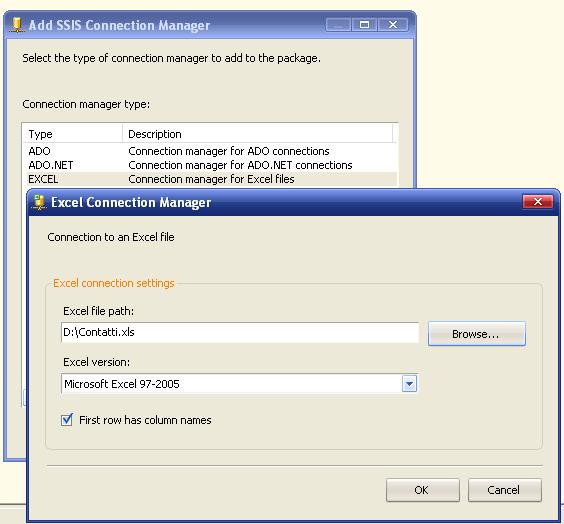
Ho spuntato il flag proprio perchè la prima riga del mio excel ha i nomi delle colonne. Ricordarsi di deselezionarlo nel caso contrario

Dopo aver confermato, ho rinominato il connection manager in Contatti.
3) Ecco i dati in anteprima ottenuti legando il connection manager alla sorgente Excel:
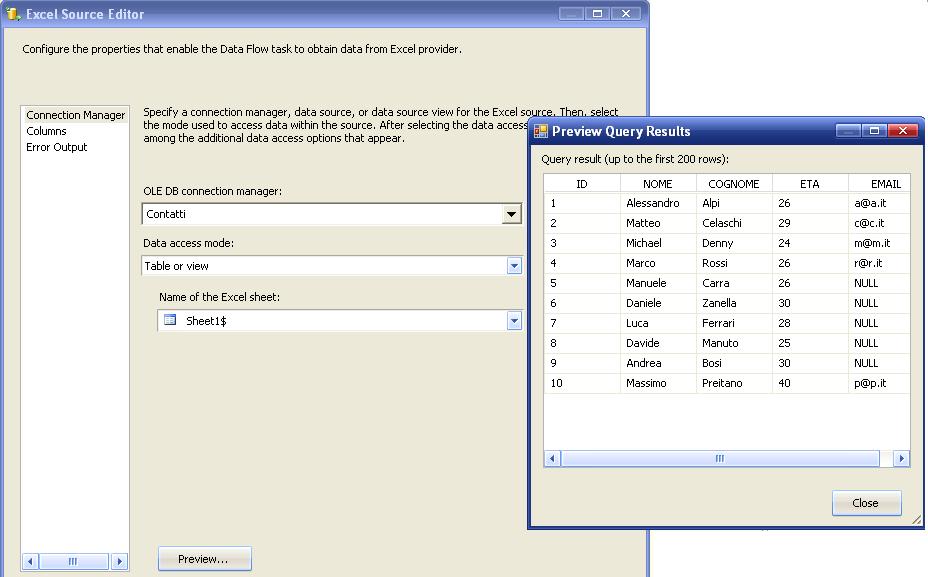
Come possiamo notare i dati con id 5,6,7,8,9 non hanno la mail valorizzata e l'informazione è NULL.
4) Ecco come gestire il null nella conditional split:
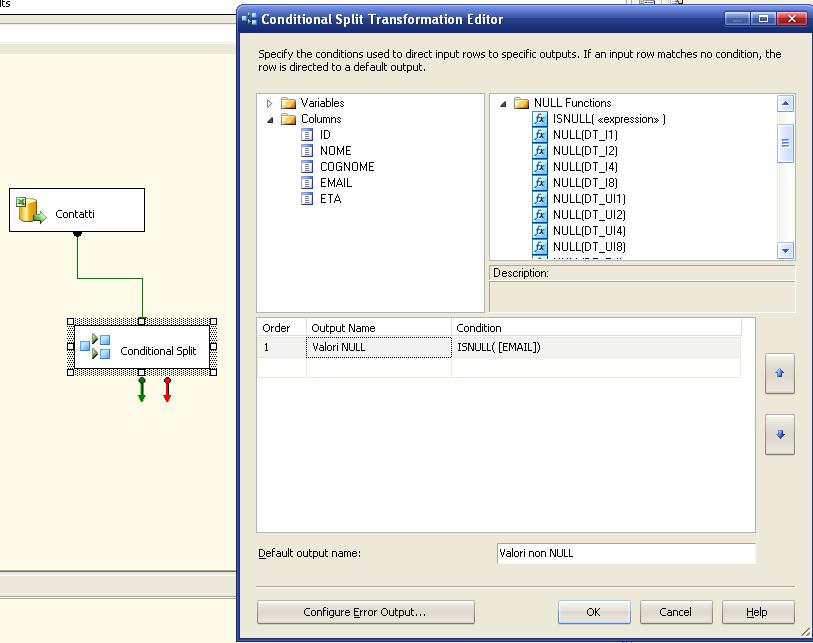
Avremo in output due rami, uno, che per noi è quello corretto, con le email valorizzate, l'altro, da gestire poichè la colonna email è NULL. Possiamo ad esempio aggiungere un derived column per inserire nel valore NULL la stringa "N/A":
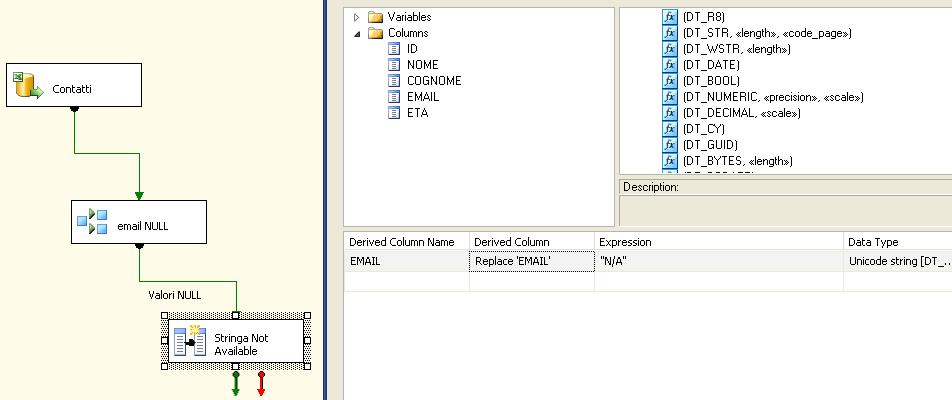
A questo punto siamo pronti ad unire i risultati per ottenere un resultset "pulito" e pronto da inserire su SQL Server.
5) Utilizzando il task Union All andiamo ad unire i dati gestiti dal Derived Column con quelli già "puliti" uscenti dalla condizione di default del Conditional Split:
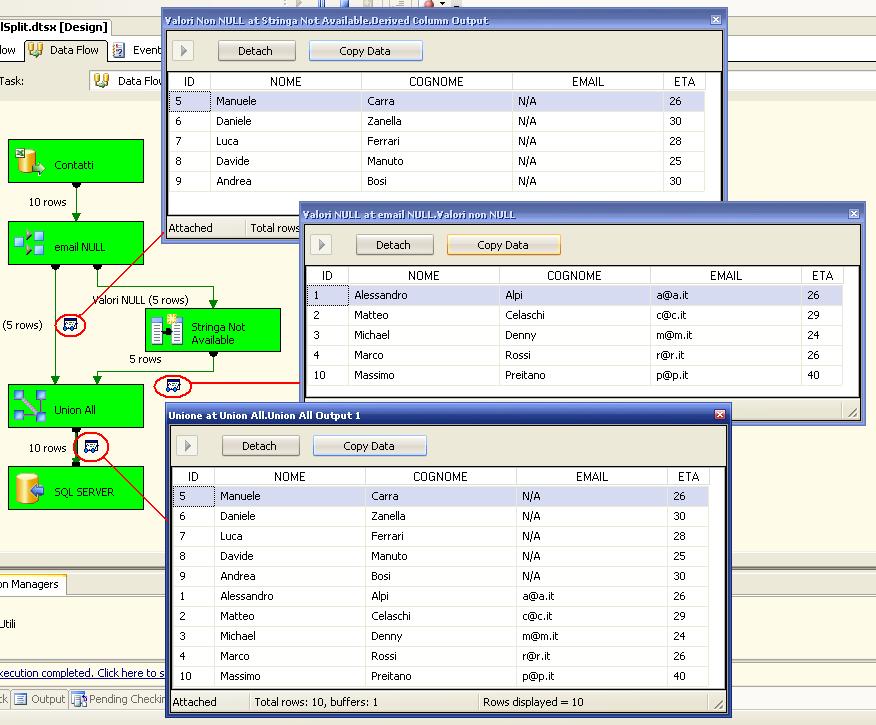
Come possiamo vedere dal primo data viewer (ricordiamo che un dataviewer è un insieme di informazioni che ci consentono di eseguire debug e stime sui dati) abbiamo i dati gestiti dal Derived Column "
Stringa Not Available". Nel secondo abbiamo i dati uscenti dal Conditional Split "
email NULL" mentre nel terzo abbiamo l'unione dei due resultset in uno solo. Questi ultimi sono i dati che effettivamente saranno inseriti in SQL Server.
Stay Tuned!
