Ritorniamo sui post di formazione, anche se so che molti di voi ora saranno già esperti di SSIS

.
L'ultima volta ci siamo lasciati con le
sorgenti, ora riprendiamo con le destinazioni.
Le possibili sono le seguenti:
Quelle comunemente utilizzate (alcune sono presenti anche nell'elenco delle sorgenti) sono la
DataReader Destination, la
Excel Destination, la
Flat File destination, la
OLEDB Destination e la
SQL Server Destination. Quest'ultimo è un task dedicato al caricamento di massa (bulk load) su di un server locale, solamente locale, mai remoto.
Per approfondire leggere
SQL Server Destination.
Ovviamente, a differenza dai source task, questi necessitano metadati in input e non ritornano metadati di output. Possiamo dire che sono la parte finale di ogni dataflow, anche se non è necessario terminare le nostre logiche con un destination task.
Come possiamo vedere dall'elenco, ci sono tre task, che non sono proprio destinazioni a tutti gli effetti:
- Data Mining Model Training- Dimension Processing- Partition Processing
Sono task dedicati a chi ha necessità di lavorare con OLAP, con la BI e/o con il datawarehousing. Gli ultimi due riguardano le parti fondamentali di un CUBO.
A grandissime linee, consentono di processare una o più dimensioni di un modello multidimensionale (dove per dimensione si intende l'entità che consente la navigazione di un CUBO) e di processare una partizione di un CUBO. Con il termine processare si intende una sorta di "compilazione", in questo caso delle dimensioni e delle partizioni di un CUBO.
Fino a che un process non è terminato, la dimensione o il cubo non sono interrogabili.
Per il primo task invece, consiglio di leggere
qui, essendo il
data mining un discorso delicato, basato su particolari algoritmi.
Le rimanenti consentono di scrivere su recordset, file raw e versioni Compact Edition di SQL Server. Per ulteriori informazioni su quest'ultima destinazione, leggere
qui.
Prendiamo una destinazione di esempio, la OLEDB Destination, e vediamo come sono composte. Facendo doppio click, la prima sezione è la Connection Manager:
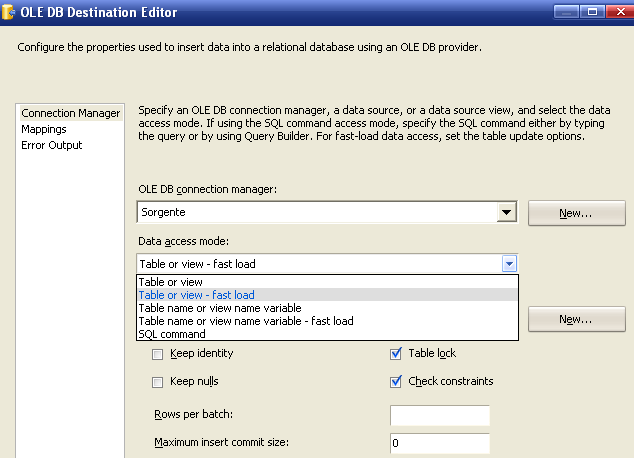
Tramite questa interfaccia è possibile definire quale connection manager utilizzare come destinazione, il livello di accesso ai dati (se possibile, per ottenere maggiori prestazioni, utilizzare il fast load) ed alcune importanti opzioni.
Keep Identity - Per imporre alla destinazione di non ricalcolare gli autoincrementanti, utilizzando quelli della sorgente (solo se fast load)
Keep nulls - Per imporre alla destinazione di copiare i null (solo se fast load).
Table lock - Per tenere bloccata la risorsa.
Check constraints - Per imporre alla destinazione di controllare tutti gli eventuali vincoli.
Rows per batch - Per indicare quante righe per batch devono essere considerate (textbox vuoto o -1 indicano mancanza di controllo sul numero di righe). Indicativamente è il numero approssimativo delle righe lette.
Maximum insert commit size - Per specificare le dimensioni del batch per le quali la destinazione OLEDB tenta di eseguire il commit
La sezione mappings indica come la sorgente deve essere riferita alla destinazione.
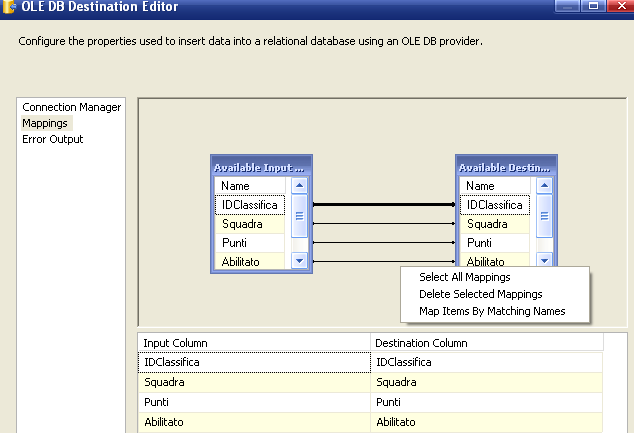
Se i nomi sono identici SSIS propone il suo mapping, in caso contrario è sufficiente indicare il corretto match nei drop down sotto, oppure fare trascinare i campi sorgente sopra a quelli destinazione. Con quest'ultima operazione i drop down si popoleranno dinamicamente.
Inoltre, premendo il tasto destro del mouse sulla zona dei legami, è possibile selezionare alcune opzioni rapide, per mappare o gestire più velocemente un numero considerevole di campi.
La sezione Error Output è del tutto identica a quella di ogni task, e quindi permette la gestione di eventuali errori.
E' molto importante valorizzare bene, nel caso degli OLEDB Destination Task, le due opzioni
Rows per batch e
Maximum insert commit size.
A questo proposito consiglio di leggere
questo link, e comunque consiglio di effettuare tante prove per capire quali valori sono i più indicati per il miglioramento delle prestazioni, non esistendo una formula specifica per calcolarli.
Stay tuned!
