Poco tempo fa, sul blog, mi è arrivata una richiesta come questa:
“Visto che in DTS, via ActiveX Script si poteva fare SkipRow e quindi saltare n righe di una particolare sorgente dati, ora come posso implementare la stessa logica?”
In SSIS, un task che risolve la problematica è il conditional split.
Con questo task è possibile definire condizioni particolari ordinate in base a una determinata priorità. Per ogni condizione impostata (con in più quella di default, che viene considerata se nessuna delle precedenti si verifica) avremo un output, da gestire come meglio si crede.
Possiamo immaginare quindi come ignorare le righe da “saltare”..
Ma facciamo un piccolo esempio:
Scenario
Ipotizziamo di avere un file di testo che contiene le informazioni relative ai movimenti di un correntista.
Si vogliono importare su un SQL Server 2005 solamente i movimenti che superano l’importo di 1000€ e redirezionare su di un nuovo file quelli inferiori, identificati come superflui ai fini dell’importazione (da skippare). Immaginiamo di avere un file di testo sorgente, che chiamiamo Movimenti.txt così formato:
1 10000 EUR D
1 100 EUR D
1 30000 EUR A
1 200 EUR D
1 5000 EUR D
1 1000 EUR A
1 200 EUR A
1 1000 EUR D
1 3000 EUR A
1 1200 EUR A
1 1300 EUR D
1 1300 EUR D
1 4000 EUR A
1 500 EUR D
1 2000 EUR D
1 1200 EUR D
Il file ha i campi separati da tabulazione. Al fine di rendere più chiaro l’esempio, tralascio la normalizzazione delle informazioni, dando solo un’idea di quello che possiamo fare con il SSIS che andiamo a descrivere. Quest’ultimo potrebbe essere formato da un dataflow, al cui interno andiamo a gestire la logica di skipping delle righe delle quali non ci interessa l’importazione. Quindi pensiamo ad una sorgente dati File Flat, ad un Conditional Split e due Destinazioni, una per il SQL Server ed una per il file degli “scarti”.
Vediamo come procedere:
Aggiungiamo il Connection Manager File Flat facendolo puntare al nostro file Movimenti.txt e definiamo le colonne IDUtente, Importo, Valuta, Tipo con i relativi tipi di dato (intero, decimale, stringa(3), stringa(1)).
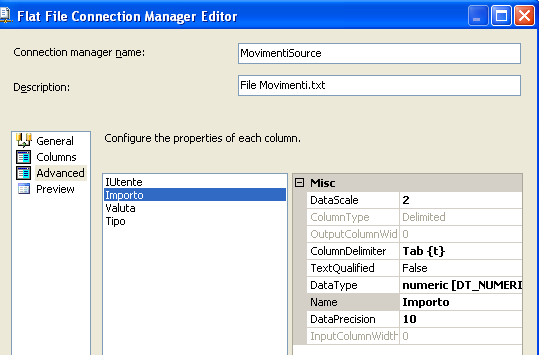
Per sapere come configurare un Flat File Connection manager, leggere questo post.
Creiamo il nostro dataflow e chiamiamolo Movimenti. Al suo interno (doppio click sullo stesso) andiamo ad aggiungere la sorgente File Flat, facendola puntare al connection manager precedentemente creato. Dopo aver definito le colonne di output (sono create dinamicamente nella sezione columns della sorgente File Flat) trasciniamo sullo stage il conditional split, rinominandolo in Skip minori di 1000.
Ora soffermiamoci sul task per darne una più accurata descrizione. Facendo doppio click su di esso otteniamo la seguente maschera:
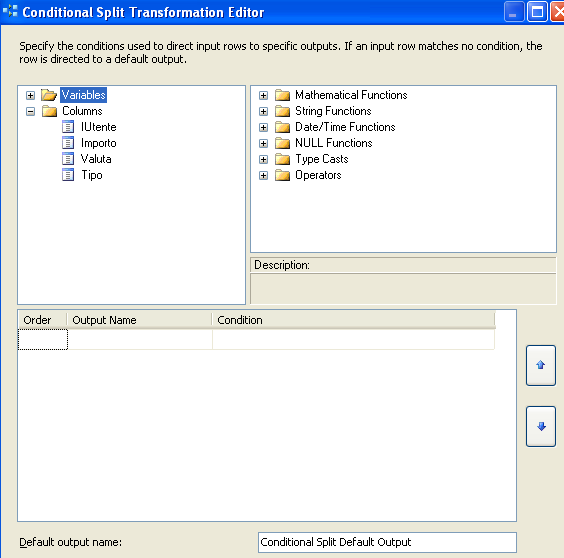
A sinistra abbiamo il treeview utile alla selezione delle variabili o delle colonne di input del task.
La parte di destra racchiude un insieme di funzioni di vario tipo, matematiche, su stringhe, su date, sui tipi di dato, ecc. È sufficiente trascinare nella parte sottostante una di queste per ottenere un aiuto sulla sintassi della funzione stessa.
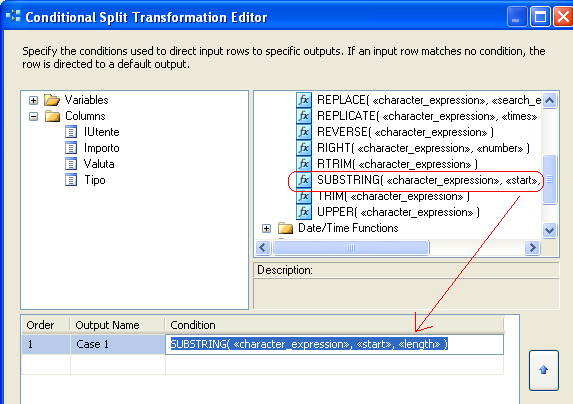
Notiamo che per ogni condizione definita, viene aggiunta una voce Case nella colonna Output Name. Quello è il nome modificabile di come la pipeline di output si presenterà dopo aver configurato il Conditional Split Task.
Aggiungiamo ora una condizione utile al nostro scopo:
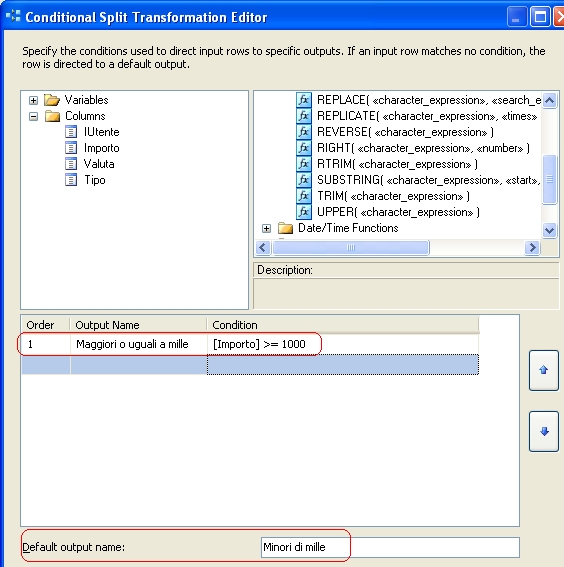
Notiamo anche il nome impostato alla condizione di default, attraverso la quale si passa, come già indicato prima, solo se le altre condizioni non sono soddisfatte.
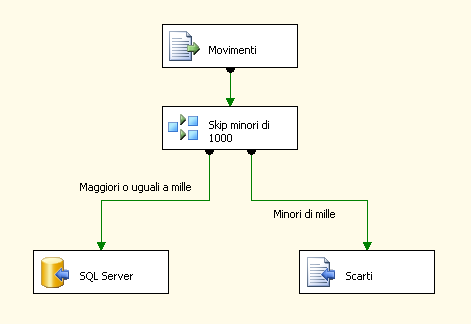
Ora creiamo un Connection Manager verso un ipotetico SQL Server 2005 (nell’esempio, utilizzo il mio server in locale, su di un database appositamente creato per l’esempio) ed un ulteriore Connection Manager per un file denominato Scarti.txt (definire le colonne di output come per la sorgente). Successivamente andiamo ad aggiungere un OLEDB Destination ed un Flat File Destination riferiti ai relativi Connection Manager. Ecco come si presenta alla fine il SSIS:
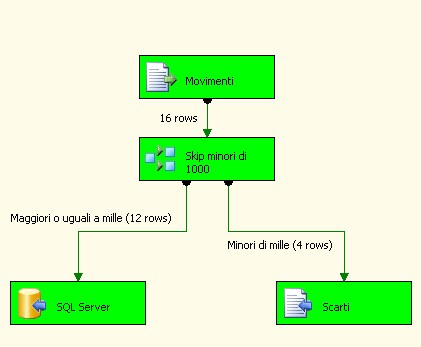
Eseguendolo otterremo il risultato desiderato (4 righe scartate):
CONCLUSIONI
Per ottenere la logica dello SkipRow di DTS è quindi sufficiente architettare un dataflow come quello appena descritto. Da notare però che nell’esempio, gli scarti vengono riposti su di un file apposito, ma se volessimo solamente ignorare le righe, sarebbe sufficiente non gestire la pipeline della condizione di default. Semplice no?
Stay tuned! 