Quando tra gli autori di un libro su SQL ci sono Plamen Ratchev (da cui più volte ho ricevuto aiuto nei forum Microsoft), Jeffrey Garbus e, soprattutto Joe Celko (senza nulla togliere al quarto, ovvero Alvin Chang), si può stare sufficientemente tranquilli che il contenuto offerto è di primissima qualità.
Ed in effetti è così, pur essendo questo libro (stranamente) passato un po’ in sordina, dato che a distanza di 2 anni dalla sua pubblicazione, possiede solo 4 recensioni (tra l’altro piuttosto positive) su Amazon USA.
Giusto per la cronaca, ecco una biografia sintetica di Jeffrey Garbus che, a quanto mi pare, coordina un po’ tutto questo gruppo di 4 autori.

Il libro è essenzialmente un corso, molto poco formale, sul T-SQL di SQL Server aggiornato alla versione 2008 R2. Pur partendo dalle basi (Select), il lettore ideale dovrebbe già conoscere tale linguaggio, dato che gli autori si concentrano maggiormente a mostrare le sottigliezze poco conosciute e soprattutto il suo migliore uso ai fini dell’ottimizzazione delle performance nell’esecuzione delle query.
Il libro è suddiviso in 3 parti.
Nella prima, che copre le prime 220 pagine delle complessive 500, si tratta del T-SQL in sé: stored procedure, funzioni, trigger, indici, cursori (ebbene sì, anche questi), viste, ecc. ecc.
Con un linguaggio estremamente informale (ma qualche volta infarcito con parole poche comuni per un lettore non madrelingua) si spiegano i dettagli come raramente si trova in altri manuali sullo stesso argomento.
Nella seconda parte, si presta un occhio di riguardo alle performance, analizzando e spiegando indici, query plan (eccellente capitolo questo), ottimizzazione delle query (un paio di capitoli anch’essi utilissimi) e persino di hardware.
Nella terza ed ultima parte, invece, si spiegano alcuni dettagli (relativamente) avanzati, quali il T-SQL dinamico, le funzioni di raggruppamento, il refactoring del codice e altri piccoli argomenti.
Gli ultimi 3 dei 25 capitoli totali sono dei case study che analizzano una situazione realmente accaduta, dove è stata inizialmente proposta una soluzione poco efficace e si è proceduti poi a migliorarla man mano.
Al termine della maggior parte dei capitoli ci sono un paio di esercizi su cui il lettore viene invitato a trovare la soluzione al problema esposto. Le risposte appaiono subito dopo, e qualche volta – come spesso accade – in T-SQL – non sono univoche, dato che più strade possono portare al medesimo risultato.
Una tra le cose che mi ha colpito di questo libro è il suo scarno aspetto grafico. Si è data infatti maggiore enfasi alla bontà del contenuto, e poca alla sua presentazione.
Ecco un’immagine presa da 2 pagine casuali del libro.

Sembra quasi un vecchio ciclostile anni ’80. Nessun abbellimento estetico. Il codice, in particolare, risulta male assemblato, con un font troppo grande e troppo spaziato, che rende la sua lettura davvero poco piacevole.
Ci sono, fortunatamente, dei piccoli box riportanti note di approfondimento scritte su sfondo grigio, ma è tutto qua. Non ci sono praticamente immagini (nessuno screenshot del Management Studio), mentre il codice, pur dotato di una discreta indentazione, soffre di un font troppo grande e troppo spazio, che ne inficia la lettura.
Non ho trovato invece refusi o problemi vari, segno che gli autori (o chi per loro) hanno svolto un buon lavoro di revisione.
Le 3 appendici, che riportano dei Case Study su cui ragionare, le ho trovato ben poco efficaci. Presuppongono la conoscenza di strutture di tabelle perfettamente sconosciute, e la maggior parte di queste pagine sono piene di codice buttato lì con pochissimi commenti, come se il lettore, solo guardando gli script, dovesse capire dove sta l’errore e come fare per eliminarlo. Pagine effettivamente sprecate.
Ed è anche uno dei rarissimi libri tecnici che non hanno reso disponibile il codice sorgente. Bisogna riscriversi tutto a mano, sempre ammesso che si voglia provare gli esempi proposti. Per la cronaca, ed anche questo è un aspetto “vintage”, come database si usa il vecchio ma glorioso “Pubs”.
Insomma, un testo comunque decisamente molto utile (pur coi suoi limiti e i suoi difetti), ricco di consigli e approfondimenti, esposto da autori che sono quanto di meglio esista su questo argomento.
Qualunque sia l’entità dell’esperienza che si può vantare su SQL Server e sul T-SQL in particolare, da questo manuale si imparerà sicuramente qualcosa di nuovo.
Sommario
Part 1 – All about programming
3 - Chapter 1 Introduction
9 - Chapter 2 SQL Basics
49 - Chapter 3 Tables
65 - Chapter 4 Views
77 - Chapter 5 Built-in Functions and Set Options
99 - Chapter 6 Programming Basics
117 - Chapter 7 Transactions
135 - Chapter 8 Cursors
153 - Chapter 9 Stored Procedures
175 - Chapter 10 User Defined Functions
181 - Chapter 11 Triggers
203 - Chapter 12 CTE
Part 2 – Focus on Performance
223 - Chapter 13 Understanding Graphical Query Plans
253 - Chapter 14 Indexes
303 - Chapter 15 Join Optimization
327 - Chapter 16 Subquery Optimization
345 - Chapter 17 Hardware
Part 3 – Advanced SQL Techniques
389 - Chapter 18 Set Oriented Programming versus Procedural Code
399 - Chapter 19 Dynamic SQL
421 - Chapter 20 Grouping Data
437 - Chapter 21 Refactoring
457 - Chapter 22 Why Other People’s Code Stinks
467 - Chapter 23 Case Study #1
479 - Chapter 24 Case Study #2
491 - Chapter 25 Case Study #3
497 – Index
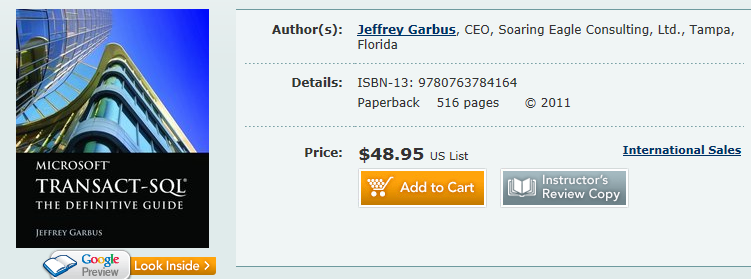
Attualmente su Amazon Italia il libro ha un prezzo piuttosto sostenuto, quasi 40 euro.