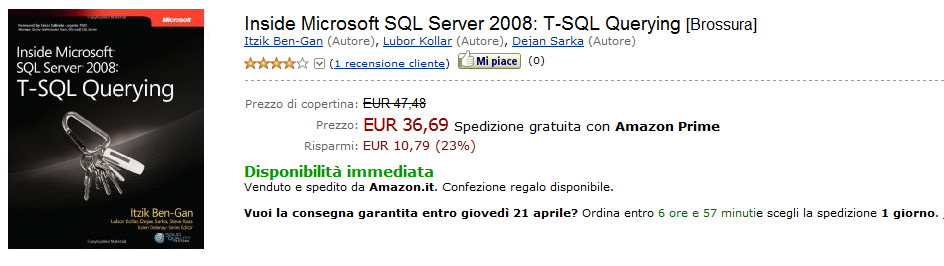
Basta dare un’occhiata al gruppo degli autori di questo libro per rendersi conto che non si tratta di un manuale qualsiasi sul T-SQL.
Innanzitutto Itzik Ben-Gan, il capitano della ciurma, è forse il maggiore esperto mondiale su questo linguaggio.
Gli altri sono ugualmente delle vere e proprie menti.
Lubor Kollar è il PM di Microsoft su SQL Server, Dejan Sarka è MVP piuttosto famoso nelle community e nei forum (pure io ho ricevuto qualche sua risposta nei forum statunitensi) e Steve Kass, oltre che ad essere anch’esso MVP su SQL Server, insegna matematica e computer science.
Le quasi 800 pagine di questo tomo, insieme all’altro libro della stessa collana Microsoft Press, “T-SQL Programming”, costituiscono il naturale evolversi dei discorsi iniziati nel primo libro, “T-SQL Fundamentals”, libro che costituisce il primo passo nell’apprendimento del SQL di casa Microsoft.
Una premessa: questo non è un manuale per principianti. Le 33 pagine del primo capitolo, in cui si introducono argomenti abbastanza basilari (e, se vogliamo, piuttosto semplici), possono dare una falsa impressione.
Il discorso si farà (molto) più duro strada facendo.
Come database su cui verranno sviluppati gli esempi gli autori forniscono (attraverso il file del codice sorgente) una versione light del famoso AdventureWorks di SQL Server 2008.
Una scelta che mi ha un po’ spiazzato, però, è stata quella di introdurre due capitoli (il secondo e il terzo, che complessivamente totalizzano quasi 100 pagine) che trattano argomenti più da livello “corso di analisi matematica all’università” che legati al mondo reale in cui si troverà ad operare uno sviluppatore SQL.
Ok, l’insiemistica, l’algebra e il modello relazionale spiegato fino al Dna possono essere argomenti affascinanti, ma la lettura di queste pagine può risultare un mattone difficilmente digeribile, per di più dall’incerta effettiva utilità sul campo.
Io li ho quasi saltati a piè pari, giusto un’occhiata per farsi accapponare la pelle e passare oltre.
La loro lettura, grazie al cielo, non pregiudica il proseguimento del libro, e direi nemmeno la propria vita di sviluppatore T-SQL.
Il gigantesco quarto capitolo – addirittura 150 pagine – vale da solo, a mio modo di vedere, metà del prezzo del libro.
È una trattazione veramente approfondita del query tuning: come ottimizzare le query, come valutare gli impatti sulle performance, come interpretare i risultati dei query plan e come gestire al meglio gli indici.
Di materiale al fuoco ce n’è tantissimo, parecchie anche le immagini dei vari piani di esecuzione analizzati e spiegati con un livello di dettaglio difficilmente riscontrabile altrove.
Questo capitolo potrebbe diventare un (piccolo) libro a sé stante, e chi è interessato a questo importante argomento di sicuro troverà pane per i suoi denti.
Occhio al capitolo 5, in cui il matematico Steve Kass torna alla carica affrontando la complessità degli algoritmi. Altre 19 pagine che si possono saltare senza troppi sensi di colpa.
Le ben 91 pagine del capitolo 6 riprendono i medesimi argomenti affrontati in maniera più superficiale nel libro T-SQL Fundamentals, ovvero subquery, CTE e funzioni di ranking.
Anche le 55 pagine del capitolo 7 riprendono, ampliandoli parecchio, i discorsi iniziati in quel libro riguardo alle Join e al modo di legare più tabelle, sempre avendo come scopo l’estrazione dei dati (ovvero l’uso di Select, e non Update o Delete).
Molto lungo anche il capitolo 8 in cui si affrontano argomenti ancora più avanzati, come le diverse operazioni per aggregare i dati (i vari Pivot e Unpivot).
Terrei a sottolineare come l’aver reso il libro – di circa 800 pagine, non dimentichiamolo – composto da così pochi capitoli, li abbia resi enormi come lunghezza. Ciò, a mio parere, non aiuta l’aspetto didattico. Se si vuole leggere completamente un capitolo, per motivi naturali si arriverà alla fine troppo stanchi per assimilarne efficacemente il contenuto. Se lo si vuole spezzare in due (o 3 o più), c’è il rischio di fare un po’ di fatica per riprendere il discorso che si era iniziato nella lettura precedente.
Decisamente più gestibile il capitolo 9 – di 33 pagine, una lunghezza ideale – che tratta delle funzioni Top e Apply dando particolare risalto a come cambiano le performance a seconda del loro diverso utilizzo.
Consiglio di assimilare nel miglior modo possibile il capitolo 10, dedicato al “Data Modification”, ovvero Update e Delete affrontate in ogni loro dettaglio.
Gli ultimi due capitoli infine, l’undicesimo e il dodicesimo, trattano argomenti un poco più avanzati, come la partitioned tables e gli alberi gerarchici.
Volendo, queste pagine, si possono saltare in una prima lettura, e tenerle al bisogno nel caso in cui servisse approfondire l’argomento.
Questa è la pagina del sito della Microsoft Learning dedicata al libro, mentre questo è il sito creato dagli autori (in particolare da Itzik).
Da qui è possibile scaricare tutto il capitolo 8 “Aggregating and Pivoting Data” (ben 83 pagine) in formato Pdf.
Si può anche scaricare il poster “Logical Query Processing”, molto utile per capire la logica in cui scorre il flusso delle query.
Purtroppo le errate non sono poche, e consiglio di partire da questa pagina con la loro sistemazione, prima di iniziare la lettura del libro.
Il file del codice sorgente, scaricabile dal sito InsideTSQL.com a questo link è piuttosto piccolo, solo 165 kB, ed una volta scompresso crea un struttura di file system così fatta.
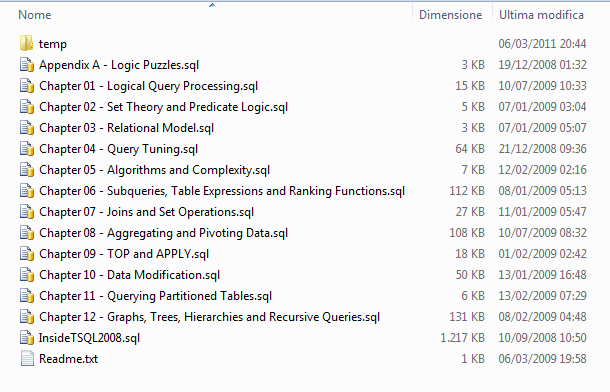
Come si vede sono ben suddivisi nei vari capitoli di appartenenza.
Successivamente si noterà anche che il codice al loro interno è indentato e commentato in maniera eccellente.
Ovviamente deve essere provato su database SQL Server 2008, dato che alcune features sono state introdotte a partire da questa versione.
Chi vuole, dopo la lettura di questo libro (o insieme), può dedicarsi al suo gemello, T-SQL Programming
che ha lo scopo di approfondire altri ulteriori argomenti iniziati sempre nel precursore di questi due testi, ovvero il T-SQL Fundamentals.
Sommario
Chapter 01: Logical Query Processing
Chapter 02: Set Theory and Predicate Logic
Chapter 03: Relational Model
Chapter 04: Query Tuning
Chapter 05: Complexity and Algorithms
Chapter 06: Subqueries, Table Expressions and Ranking Functions
Chapter 07: Joins and Set Operations
Chapter 08: Aggregating and Pivoting Data
Chapter 09: TOP and APPLY
Chapter 10: Data Modification
Chapter 11: Querying Partitioned Tables
Chapter 12: Graphs, Trees, Hierarchies and Recursive Queries
Appendix A: Logic Puzzles
Qua sotto i dettagli del sito Inside T-SQL.

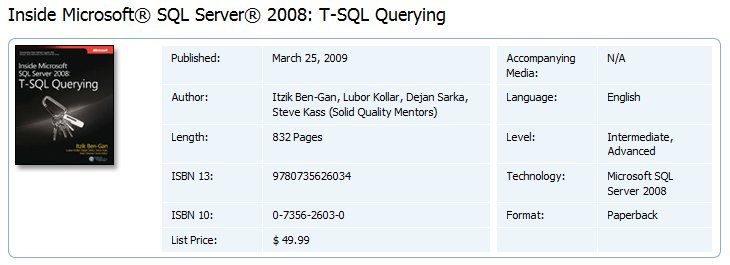
Su Amazon Italia il libro viene venduto a circa 36 euro.