Concludiamo con la carrellata dei task del control flow. In questo post parleremo di:
- Script Task
- XML Task
- Data flow TaskIn realtà esistono alcuni altri task, come il
Bulk insert task, il
Send email task, il
Web service task, alcuni task relative all’OLAP ed al Data Mining e via discorrendo.. Per ora parleremo solo dei suddetti task, in modo da avere la parziale conoscenza dei task più utilizzati. Analizziamoli in dettaglio..
Script Task
Tramite lo
Script Task si accede all’ambiente
Microsoft Visual Studio for Applications (VSA) nel quale è possibile scrivere ed eseguire codice (
solamente in VB.NET).
N.B. Esiste comunque un
ActiveX Task che permette di lavorare con gli activeX dei DTS di SQL Server 2000. Si tratta di un task molto semplice che consente di scrivere script in jscript, vbscript, e tutti quei linguaggi di scripting presenti sulla macchina dove è installato SSIS.
Lo
Script Task ha tuttavia notevoli vantaggi rispetto alla precedente versione:
- la presenza di un
editor integrato in Visual Studio con Intellisense
- i
breakpoint a livello di codice per migliorare il debug dei SSIS
- il passaggio di
parametri allo script
- la
precompilazione in formato binario per aumentare le prestazioni a runtime
Come al solito, facendo doppio click sul task, appare la sezione
General, con le consuete informazioni su nome e descrizione. Spostandosi sulla sezione
Script appare la seguente pagina:
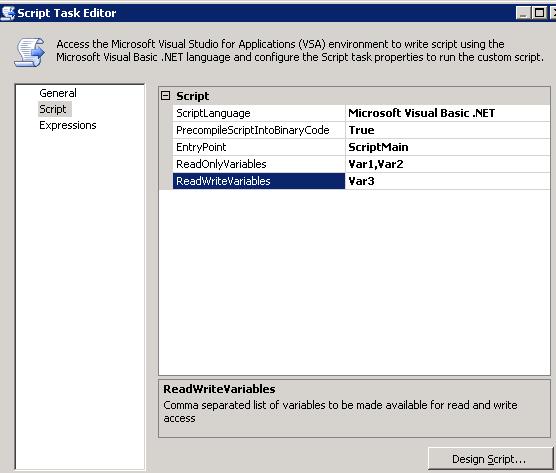
La proprietà
ScriptLanguage consente di selezionare con quale linguaggio del framework è possibile scrivere codice. Per ora è possibile utilizzare solamente VB.NET, ma nelle prossime versioni di SQL Server potrebbe essere possibile sceglierne altri.
PrecompileScriptIntoBinaryCode è una proprietà che, se impostata a true, permette di precompilare il codice in formato binario, in modo da aumentare la velocità, e quindi le prestazioni, dello script in esecuzione.
Questa proprietà deve essere obbligatoriamente valorizzata a true se il SSIS viene eseguito su sistemi a 64bit o come SQL Server Agent Job.EntryPoint definisce il nome della classe contenente il metodo Main, chiamato al momento dell’esecuzione, di default
ScriptMain.
Poi vi sono due proprietà molto importanti per il passaggio dei parametri, la
ReadOnlyVariables e la
ReadWriteVariables, entrambe liste di variabili separate da virgola. Le prime sono di sola lettura, mentre le altre sono di lettura/scrittura. Purtroppo non esiste alcun richiamo alle variabili già dichiarate nel pacchetto (come combo di selezione o finestre di popup con elenco, che ci vorrebbe proprio), quindi è necessario scriverne a mano i nomi
Case Sensitive precisi. Un po’ scomodo

.
In basso a destra troviamo il tasto
Design Script, il quale permette di aprire l’editor integrato in Visual Studio. In esso è possibile scegliere le modalità di
debug, impostare
breakpoint ed usufruire dell’
intellisense.
Qui di seguito un piccolo esempio:
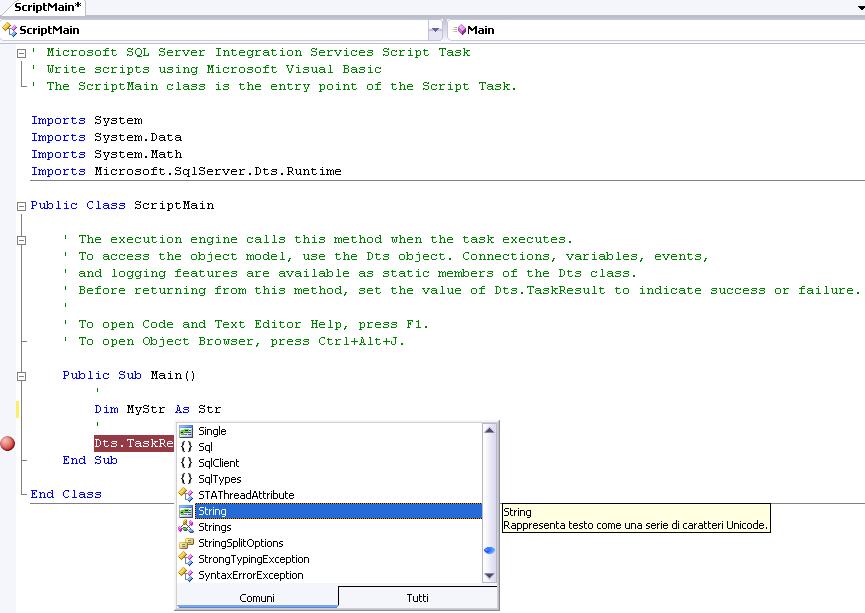
Ovviamente tutto quello che si può scrivere in uno
Script Task verrà approfondito in uno dei prossimi post. Per ora limitiamoci ad averne una visione generica ed a sapere che l’unico linguaggio disponibile è VB.NET.
XML Task

E’ uno dei nuovi task più utili di SSIS. Consente di eseguire varie operazioni su file XML, eccole elencate:
- Unisce una serie di file xml in un unico file
- Formatta un file xml applicando un XSLT
- Esegue query XPATH per ricavare porzioni di un file xml
- Estrae le differenze tra due file xml rappresentandole in un Diffgram XML
- Valida un xml seguendo le specifiche di DTD o di un XSDLa finestra in cui vengono definite le modalità di utilizzo è la General. In base al valore selezionato nella proprietà
OperationType appare una maschera differente. La OperationType può assumere i seguenti valori:
- Validate
- XSLT
- XPATH
- Merge
- Diff
- PatchMentre le prime cinque opzioni rispecchiano quanto detto nell’introduzione dell’XML Task, l’ultima (patch) consente di applicare l'output di un'operazione Diff per la creazione di un nuovo documento xml.
In ognuna delle operazioni è sempre presente una sezione Input, una Output ed una Second Operand.
La prima identifica il file xml su cui eseguire l’operazione oppure il primo dei due xml da unire o di cui calcolare la differenza. Al di fuori della
OperationType si hanno:
-
SourceType, tipo del sorgente, File Connection o Variabile.
-
Source, in base alla precedente, Un connection manager o una variabile contenente un percorso.
La sezione Output consente di salvare il risultato di uscita in un file o in una variabile che identifica un percorso di file. Rispetto alla precedente sezione permette di scegliere se salvare o meno il risultato, tramite la proprietà
SaveOperationResult, e se sovrascrivere il file esistente, tramite la
OverwriteDestination.
Infine, la sezione
Second Operand, prende il valore del secondo operando utile all’operazione prescelta. Il second operand può essere un altro file xml, la query XPATH oppure anche l’XSD di validazione.
Anche qui è necessario specificare il tipo, con la proprietà
SecondOperandType, che può valere Direct Input, File Connection oppure Variable, e il percorso, con la proprietà
SecondOperand.
Data Flow Task
Il Data Flow Task è uno dei notevoli miglioramenti di SQL Server 2005 Integration Services. Pur rimanendo un task del control flow, sul quale, per altro, viene collocato, possiede in sè tutte le logiche di trasformazione del package. Si tratta di un contenitore di altri task, che però non sono disponibili nel control flow. In esso ogni logica di trasformazione e di importazione di dati passa attraverso alle seguenti tipologie di task:
-
Sorgenti, oledb, excel, access, e quant’altro..
-
Destinazioni, oledb, recordset, excel, e così via..
-
Trasformazioni, Lookup, Colonne derivate, Condizioni, Multicast, Union All, Merge join, e via discorrendo..
Si tratta di quello che prima potevamo limitatamente (e poco comodamente) fare nei DTS con i data pump, anche se dire questo è veramente riduttivo. I data flow sono una grande estensione della versione precedente, considerato il fatto che utilizzano oggetti del framework e che danno la possibilità di scrivere logiche più varie rispetto a quanto i DTS potevano fornire.
Siccome possono contenere altri task, è bene definire la differenza tra i data flow e il control flow:
-
Il control flow è uno solo, i data flow possono essere molteplici-
Il control flow non passa dati tra un task e l’altro (il task è un’unità di lavoro singola), mentre il data flow ragiona proprio passando dati e metadati tra task
-
Il control flow gestisce le logiche del work flow (process oriented) e quindi le priorità e le condizioni tra un task e l’altro, il data flow trasporta i dati (information oriented) tramite i legami e le condizioni definite
Qui abbiamo dato solo un’anticipazione del task più importante dei SSIS, ma in futuro avremo modo di approfondirne il contenuto, magari con qualche esempio. Soprattutto i data flow, che, come già detto, hanno logiche interne teoricamente illimitate.
Alla prossima!