| Archivio Posts | |
Anno 2018
Anno 2017
Anno 2016
Anno 2015
Anno 2014
Anno 2013
Anno 2012
Anno 2011
Anno 2010
Anno 2009
Anno 2008
Anno 2007
Anno 2006
|
|
 Control Flow Tasks – Execute SQL Task Control Flow Tasks – Execute SQL Task
Nella toolbox del control flow troviamo tantissimi task disponibili, ma noi considereremo solamente quelli più comuni, in modo da fornire una overview sulle potenzialità di Integration Services. Parleremo di: - Execute SQL Task
- Execute Process Task
- Execute Package Task
- File System Task- FTP Task
- Script Task
- XML Task
- Data flow TaskExecute SQL Task
L’Execute SQL Task ci permette di eseguire degli statement SQL, degli script T-SQL e delle stored procedure, offrendo inoltre utili interfacce per la gestione del passaggio dei parametri, il mapping dei resultset di ritorno e la definizione di Expression dinamiche sulle proprietà del task.
Una volta trascinato dalla toolbox, viene segnalato un errore. Nessun problema, si tratta del mancato collegamento di un connection manager tramite il quale effettuare le operazioni. Facendo doppio click sul task ci si presenta la seguente maschera:
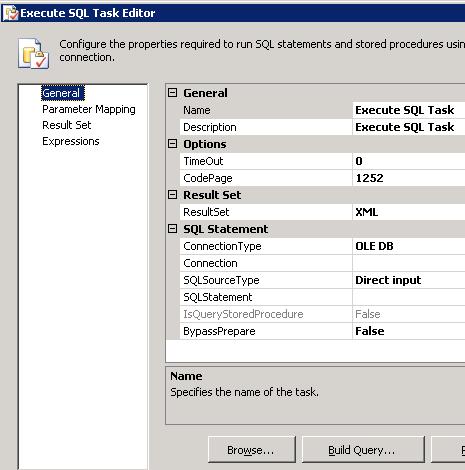
Le sezioni, indicate sulla sinistra, sono:
- General
- Parameter Mapping
- Resultset
- Expressions
Nella sezione General è possibile indicare le proprietà generiche del task, come nome, descrizione, connection manager, provider della connessione e eventuale codepage. Ma non solo. Infatti è di grande importanza la proprietà SQLSourceType, che ci permette di indicare se il task dovrà eseguire un SQL statement scritto a mano (direct input), preso da una variabile (variable), oppure connettersi ad un file (file connection). Altra proprietà da non tralasciare è la ResultSet, che può valere None, se non abbiamo resultset in uscita, Single row, se abbiamo solo una riga, Full Resultset se abbiamo una o più “tabelle”, e XML se vogliamo ritornare una stringa XML. Indicando una qualunque opzione diversa da None si attiverà la sezione Resultset, che ci si propone come segue:
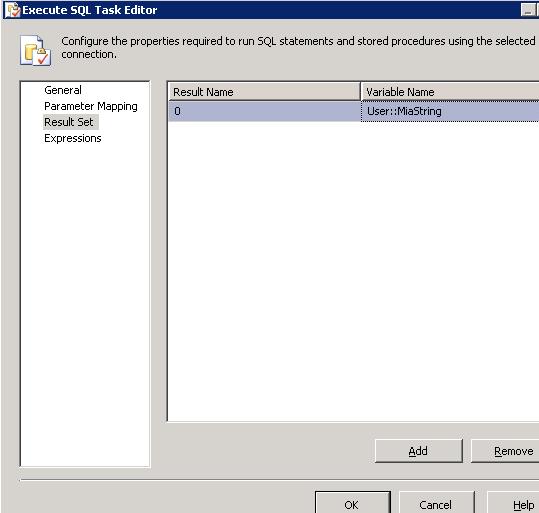
Nel caso in cui il resultset sia una sola riga è sufficiente mappare ad ogni campo una variabile.
N.B. Nella prima colonna indicare l’indice 0-based del campo e nella seconda ricordarsi che la variabile deve essere esattamente dello stesso tipo di quello del campo.
Se il resultset è impostato su full resultset è sufficiente indicare la variabile su cui l’intero resultset verrà appoggiato.
N.B. Nella seconda colonna l’unico tipo disponibile per le variabili mappate è Object. Quindi Object deve essere il tipo per una variabile che conterrà un resultset.
Per l’xml ci si comporta come per il full resultset
La sezione Parameter mapping permette di specificare eventuali parametri di input output dello statement SQL, ad esempio di una stored procedure. Ci appare come segue:
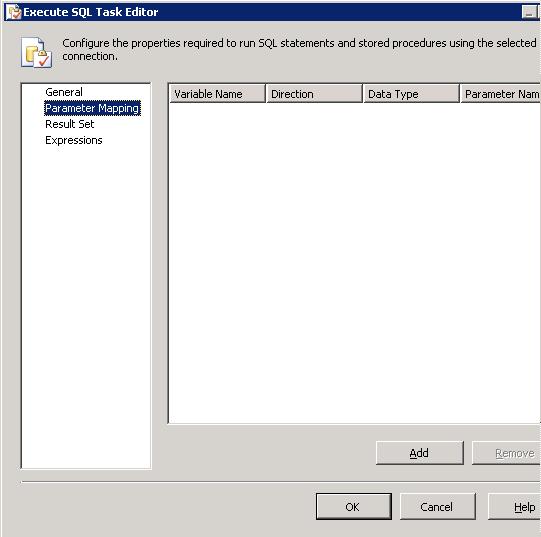
Basta semplicemente indicare la variabile da passare come parametro, la direzione (input, output o ReturnValue), il tipo (fornito dal framework, non si tratta di tipi database) e nome del parametro.
Ovviamente è necessario indicare nello statement SQL gli eventuali parametri (ad esempio rappresentati con “?” se si tratta della comune sintassi OLEDB). L’ordine del mapping dei parametri deve corrispondere all’ordine indicato sullo statement SQL.
Come per molti task, anche qui sono presenti le Expressions. Per ora limitiamoci a dire che sono espressioni valutate a runtime che impostano dinamicamente le proprietà del task. Come già detto, dedicheremo un post solo a questo argomento.
Nel prossimo post continueremo a parlare dei task del control flow.
Stay tuned 
 lunedì, 08 mag 2006 Ore. 18.39
|
| Statistiche |
- Views Home Page: 628.368
- Views Posts: 1.112.709
- Views Gallerie: 685.333
- n° Posts: 484
- n° Commenti: 273
|
|