Il lookup transformation task è un componente in grado di effettuare query di ricerca mirata tramite equi-join dei dati di input ed un particolare oggetto referenziato.
Tra i dati di input ed i dati di output deve esistere la corrispondenza di almeno una riga in base al criterio di join definito nell'editor apposito.
Nel caso in cui il match non sia realizzato, viene restituita un eccezione.
E' un task molto potente e molto spesso utile per la BI. Pensate ad un ambiente DataWareHouse e all'esigenza di ricavare la chiave surrogata di una particolare entità conoscendone solo alcune informazioni.
I suoi principali vantaggi sono:
- Effettua lookup per riga quindi rende più controllabile e gestibile il flusso dati
- Permette la restrizione dell'utilizzo della memoria
- Permette di implementare logiche di inserimento incrementale delle righe, controllando preventivamente l'esistenza delle stesse
- Permette il caching dei dati di cui poi vi sarà il match
Ma attenzione, perchè porta con se anche svantaggi da considerare in analisi:
- Lavorando per riga, diminuisce le prestazioni, quindi ove possibile, sostituirlo con query o task più intelligenti
- Se non trova un match restituisce un'eccezione e, potenzialmente, blocca il flusso dei dati
- Durante la fase di cache impiega molto tempo per preparare i dati, ma questo è attribuibile anche a come il modeling del database è stato studiato
- Ha cali di prestazioni se non ottimizzato, quindi un suo utilizzo standard è sconsigliato per moli di dati molto capienti
- Ritorna solo la prima riga di cui si ha match, non un gruppo (e questo può essere un limite voluto a livello di progettazione, ricava solo un record per una chiave logica)
Ma facciamo un esempio (molto semplificato) per capire il funzionamento del Lookup transformation e per cercare di ottimizzarlo; consideriamo un'ipotetica tabella dei fatti così formata:
CREATE TABLE Fatti
(
IDFatto int IDENTITY(1,1) NOT NULL,
IDCliente int NOT NULL,
DataRiferimento smalldatetime NOT NULL,
Stipendio decimal(8,2) NOT NULL,
CONSTRAINT PK_Fatti PRIMARY KEY CLUSTERED
(
IDFatto
)
)
ed una tabella dimensione clienti:
CREATE TABLE DimClienti
(
IDCliente int IDENTITY(1,1) NOT NULL,
CodiceFiscale Char(16) NOT NULL,
Nome varchar(30) NOT NULL,
Cognome varchar(30) NOT NULL,
CONSTRAINT PK_DimClienti PRIMARY KEY CLUSTERED
(
IDCliente
)
)
Ipotizziamo inoltre di ricevere in input un file di testo contenente alcuni dati utili alla tabella fatti, ma con il codice fiscale indicato per il cliente. In poche parole, tramite quel codice, dovremmo ricercare sulla tabella dei clienti l'id del cliente ad esso associato per poi inserire il record nella tabella
Fatti.
Il ssis risultante sarà simile a questo:
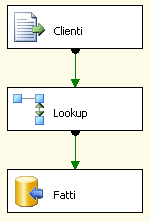
Qui non è gestita la parte di gestione dell'errore, ma per l'esempio ipotizziamo che nel file vi siano dati già presenti sulla tabella su cui faremo lookup. Quindi, avremo un flusso con i codici fiscali (e non solo) e per ogni codice fiscale faremo lookup verso la tabella
DimClienti per ottenere la chiave surrogata da inserire poi nella tabella dei fatti. Analizziamo ora il task di lookup:
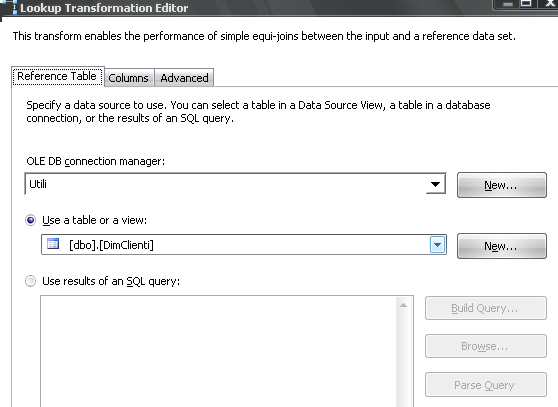
Nella prima schermata (Reference Table) selezioniamo la connessione e l'oggetto su cui fare l'operazione di ricerca mirata
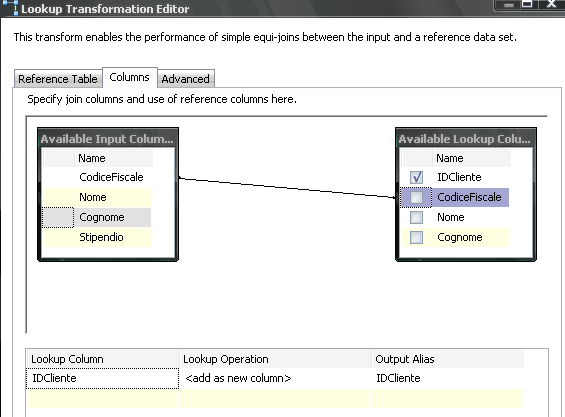
Nella seconda (Columns) andiamo a mappare i campi per il match
Per ottimizzare il componente lookup, un primo passo è quello di rimuovere le informazioni in eccesso. Procedere come visto fin'ora porta ad uno spreco di risorse. Infatti, durante l'operazione di caching del lookup transformation task, il caricamento delle colonne in più non fa altro che sprecare risorse. Addirittura, nell'area
progress viene stampato un warning. Ovviamente questo non è un esempio parlante, ma pensando ad una DimClienti dotata di più campi e con tantissimi record, eliminare informazioni inutili migliora non di poco le prestazioni.
Ecco come procedere, partendo dalla clip Reference Table:
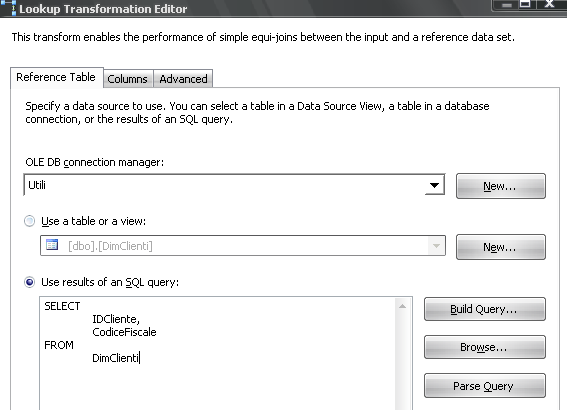
Fare quindi attenzione alle informazioni che realmente ci servono, in questo caso, solo il
CodiceFiscale e l'
IDCliente.
Di conseguenza avremo nella sezione Columns:
Ridurre la quantità delle informazioni ritornate è un ottima mossa per ridurre anche la quantità di memoria utilizzata.
Per aumentare ancora le prestazioni delle operazioni di lookup, è consigliabile l'utilizzo di un indice sul campo su cui verterà l'equi-join:
CREATE UNIQUE NONCLUSTERED INDEX UK_DimClienti_CodiceFiscale ON DimClienti
(
CodiceFiscale
)
In questo modo, ogni lookup risulterà effettivamente più veloce ed il seguente setting sulla memoria usata sarà veramente efficiente.
Quindi, una volta sull'area Advanced, ottimizziamo ancora il comportamento del componente, impostando correttamente la parte di
Memory Restriction.
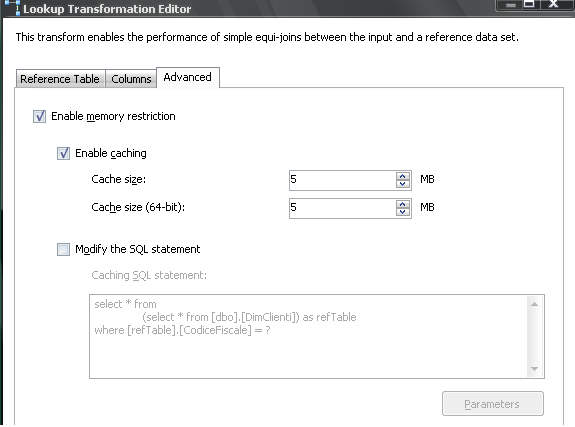
Tra le impostazioni di memory restriction, la più importante è la gestione della cache. In base alla situazione reale è infatti possibile abilitare la cache interna di SSIS. Tutte le query effettuate per riga vengono aggiunte fino a riempire la quantità di cache massima consentita. Quindi SSIS interrogherà il DB solo se non trova già righe nella sua cache appositamente creata. Riducendo la quantità di memoria con la "scrematura" delle colonne definita sopra, creando opportuni indici e configurando adhoc il caching, le prestazioni del task migliorano notevolmente.
Stay tuned!
