Proseguiamo oggi con la spiegazione dettagliata dell'esempio di cui si è parlato nella prima puntata..
In precedenza abbiamo parlato dell'elenco dei file
PREFISSO_DATACOMPETENZA_DATACREAZIONE.TXT. Supponiamo che i nostri file si trovino in un percorso preciso
"D:\Dev\" ad esempio. Per prima cosa, come indicato alla fine della 1a puntata, dobbiamo creare un
datatable che conterrà l'elenco di tutti i file presenti in quel percorso ed uno che conterrà solo i file validi (solo quelli che hanno
DATACREAZIONE più recente a parità di
DATACOMPETENZA). In secondo luogo dovremo popolare il primo datatable, che sarà il source del nostro
dataflow. Questi primi due passi sono implementati tramite i seguenti script, il primo crea i due datatable, il secondo popola solo la sorgente:
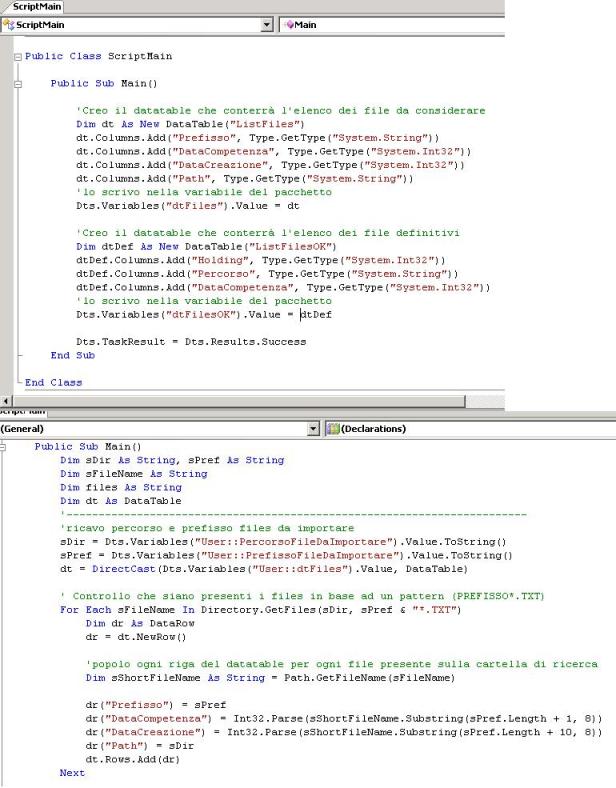
A questo punto ci si può spostare sul dataflow per arrivare alla parte centrale dell'esempio.
Come sorgente dati utilizziamo uno
Script Transformation Task in modo da far confluire i dati nel
buffer che lo stesso task ci fornisce.
Ecco come impostarlo:
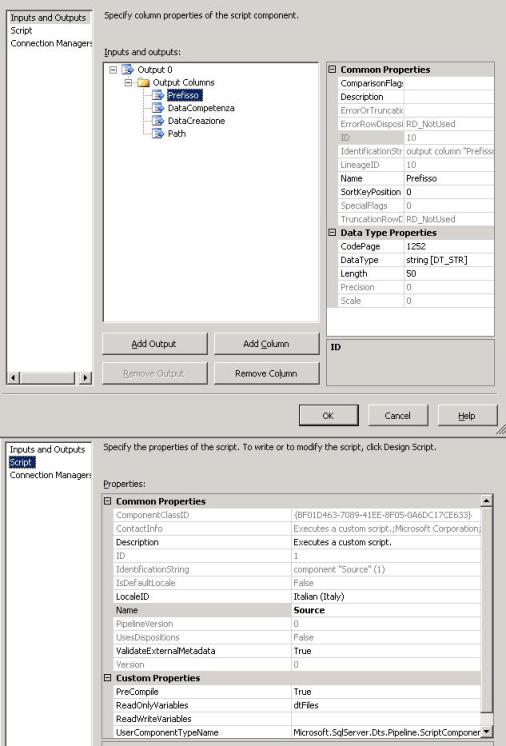
Nella sezione di "
Inputs and Outputs" aggiungiamo nelle Output Columns le colonne del nostro datatable sorgente (scegliendo nome e tipo adatto al contenuto). Abbiamo così creato la struttura del buffer di output, sorgente del dataflow.
Nella sezione "
Script" passiamo come "readonly variable" il nostro datatable sorgente, che nell'esempio si chiama dtFiles.
Clickando sul bottone "
Design script" andiamo ad inserire il seguente codice, che altro non fa che inserire i valori della sorgente dati nel buffer precedentemente impostato.
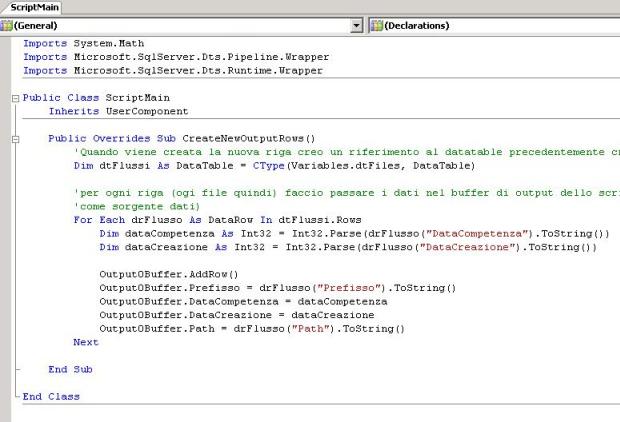
Una volta impostato il buffer dobbiamo dividere il flusso di dati in due. Per ottenere ciò utilizziamo il
Multicast task.
A questo punto abbiamo più canali (a noi ne bastano due). Il primo ramo passerà tramite un
Aggregate task, il quale ci permetterà di aggregare le informazioni del buffer come meglio si crede. Nel nostro esempio avendo le informazioni di
PREFISSO,
DATACOMPETENZA,
DATACREAZIONE, eseguiremo la group by sui primi due, e la MAX sulla Data di creazione, come segue:
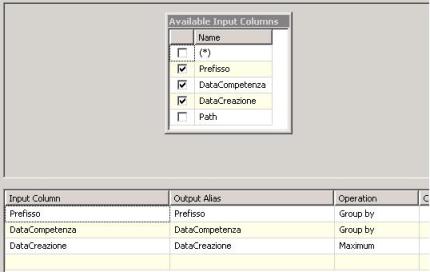
Dopo aver aggregato, ordiniamo tramite il
Sort task (nel nostro esempio ordineremo per
PREFISSO,
DATACOMPETENZA e
DATACREAZIONE).
Il secondo ramo si occuperà unicamente di ordinare i dati nello stesso modo in cui sono stati ordinati nel primo. Questo perchè i due flussi logici di dati alla fine si riuniranno all'interno di un task
Merge Join il quale si occuperà di unire i dati uscenti dal primo ramo (solo le
DATACREAZIONE più recenti) con quelli del secondo, in inner join. Ecco come il merge join dovrà essere configurato:
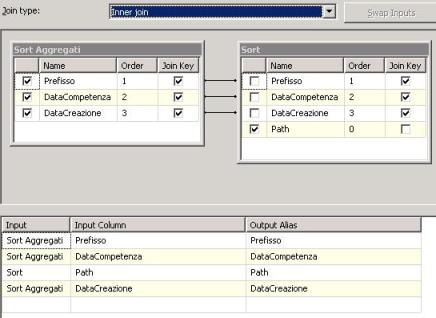
Quello che si ottiene è molto semplice, due tabelle (grazie al multicast), la prima delle quali contiene solo i file prefisso*.TXT con data di creazione più recente a parità di data di competenza (ordinati per i tre campi PREFISSO, DATACOMPETENZA, DATACREAZIONE), e la seconda che li ha tutti con il medesimo criterio di ordinamento. Mettendo in inner join si ottengono solamente i file della prima tabella, corredati degli attributi (presi dalla seconda).
Nell'esempio, il resultset è impostato su di un "
Recordset Destination" e tramite questo task poi viene passato ad una variabile del pacchetto in modo che sia fruibile anche altrove. Ad esempio, potremmo utilizzare la variabile per ciclare un caricamento di file (quelli indicati nel resultset), oppure per impostare dinamicamente la source di un
XML source task, e così via.
Inoltre, come criterio di join, abbiamo utilizzato la
INNER, ma nulla ci vieta di utilizzare le altre due possibilità,
LEFT OUTER e
FULL OUTER, in modo da considerare anche i dati che non rispettano il criterio di relazione (nel nostro esempio, potrebbe essere utile invertire l'ordine delle tabelle ed eseguire la LEFT OUTER JOIN per considerare anche i file non "validi", in modo tale da cancellarli).
Abbiamo visto quindi come può essere utile creare le nostre strutture ed utilizzarle all'interno del pacchetto. Ricordiamoci comunque di non abusare degli script se non è necessario, soprattutto quando Business Intelligence Development Studio potrebbe fornire strumenti che non solo aumentano la leggibilità del package, ma anche le prestazioni.
Spero questo possa esservi di aiuto, considerato il fatto che si può applicare a logiche differenti dall'esigenza che mi si è presentata..
Alla prossima..