Una delle innovazioni dei SQL Server Integration Services sono i Data Flow.
In SQL Server 2000 avevamo i "Data Pump" e le relative trasformazioni, ma non facciamo l'errore di paragonarli ;-)
Logicamente si tratta sempre di trasformazioni di dati, ma il modo con cui esse vengono implementate è di gran lunga differente. I Data Flow infatti lavorano pesantemente con una logica a metadati e soprattutto utilizzano strutture fornite dal .NET Framework per veicolare grosse quantità di dati, pur non avendo cali di prestazioni, anzi, i miglioramenti sono visibili da subito. Un Data Flow può essere considerato come un container delle logiche di trasformazioni ed è proprio qui il punto forte dell'infrastruttura. Al suo interno esiste un numero elevato di task che possono essere utilizzati nei modi più vari, estendendo quelli che prima erano i limiti dei data pump.
I task sono suddivisi in tre sezioni:
- Source
- Transformation
- DestinationNelle source abbiamo le sorgenti di dati, come ad esempio
XML,
DataReader,
OLEDB,
File Flat,
Excel..
Nelle destination abbiamo destinazioni rivolte all'OLAP (
Dimension Process,
Partition Process), verso
SQLServer e Mobile,
Recordset, nonchè quelli indicati nelle sorgenti.
Nelle transformation vi sono task per eseguire aggregazioni, conversioni di tipi di dati, colonne derivate, scripting..
Ognuno di loro meriterebbe ampio spazio di discussione, ma preferisco soffermarmi sulla possibilità di interagire con i
dataset/datatable all'interno dei dataflow.
Prendiamo il seguente esempio:
In una cartella ho un elenco di file, ognuno dei quali, nel nome, possiede le seguenti informazioni:
PREFISSO_DATARIFERIMENTO_DATACREAZIONE.TXT
Tutti i file sono creati da processi automatici. E' possibile inoltre che per la stessa DATARIFERIMENTO (che è una data contenuta nel flusso, ad esempio) venga rielaborato il processo di creazione, causa un qualunque errore nella produzione dei dati oppure rifacimenti on demand.
Di conseguenza avremo più file con la stessa DATARIFERIMENTO, ma con diversa DATACREAZIONE.
Supponiamo che il cliente voglia considerare solo l'ultimo creato. Ecco che un dataflow può esserci di aiuto. Possiamo infatti strutturare le informazioni contenute nel nome del file in un datatable, creato via script, e aggregare le informazioni in modo tale da raggiungere il nostro scopo. Ecco un esempio di data flow.
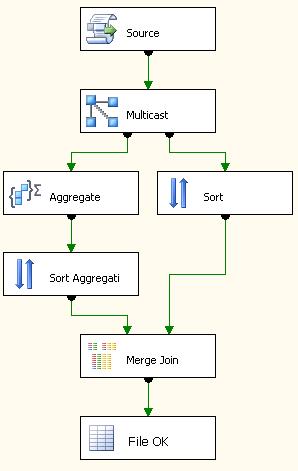
il corrispondente "
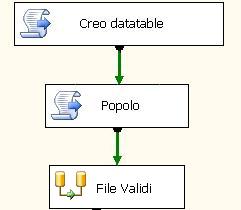
control flow" (ovvero il designer a monte, in cui scrivo i dataflow, i container e tutta il resto tei task) è il seguente.
In esso creo il datatable tramite script (purtroppo è supportato solo VB.net), lo popolo in base a mie condizioni (ad esempio un ciclo sui file sopra descritti) e lo scrivo in una variabile del pacchetto. In questo modo la variabile è visibile ed utilizzabile nel dataflow.
Rimando alla prossima puntata la spiegazione della logica completa e approfondita, visto che potrebbe servire anche per altre casistiche, meno specifiche..
stay tuned
