Con i set di caratteri (character set/class), si può dire al motore regex di fare il match di uno o più caratteri diversi. Semplicemente mettendo i caratteri di cui volete fare il match all'interno di parentesi quadrate. Ad esempio se si vuole fare il match di una 'a' o di una 'e', utilizzate [ae]. Potreste utilizzarla così "Aziend[ae]", per fare il match di "Azienda" o di "Aziende".
Un set di caratteri esegue il match di UN SOLO CARATTERE. L'ordine dei caratteri all'interno del set non è importante. Il risultato è identico.
E' possibile utilizzare un trattino all'interno del set di caratteri, in modo tale da specificare un
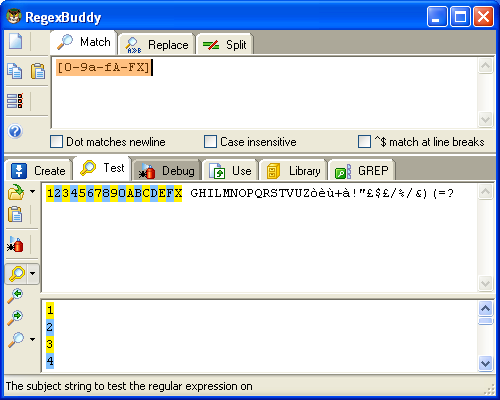
range di caratteri: "[0-9]" fa il match di una
singola cifra compresa da 0 a 9. E' possibile utilizzare più di un range all'interno dello stesso set: "[0-9a-fA-F]" fa il match di un singolo carattere esadecimale. Puoi anche unire range con singoli caratteri: "[0-9a-fA-FX]" fa il match di un numero esadecimale oppure di un carattere singolo X.
 - SET DI CARATTERI NEGATI
- SET DI CARATTERI NEGATI
Introducendo un ^ (caret) subito dopo l'apertura della parentesi quadrata, il set di caratteri sarà "negato", cioè i caratteri che entreranno a fare parte del match, saranno solo quelli
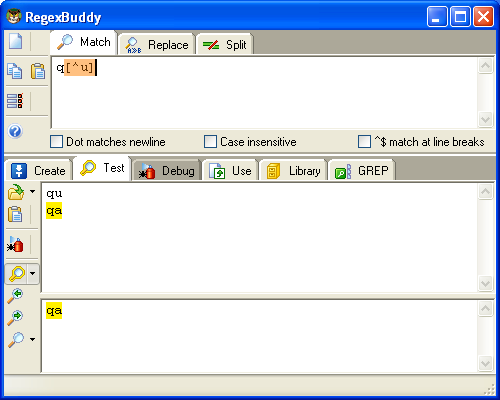
esclusi dal set. A differenza del punto (set di caratteri che tratteremo in un post a parte), un set di caratteri negati implica il match anche dei caratteri "invisibili", come il ritorno a capo, spazi e tab (ecc...). E' importante ricordare che un set di caratteri negati esegue comunque sempre il match di caratteri. "q[^u]"
non vuol dire: "una q non seguita da una u". Vuol dire: "una q seguita da un carattere che non sia una u".
 - CARATTERI SPECIALI (METACARATTERI) ALL'INTERNO DI SET DI CARATTERI
- CARATTERI SPECIALI (METACARATTERI) ALL'INTERNO DI SET DI CARATTERI
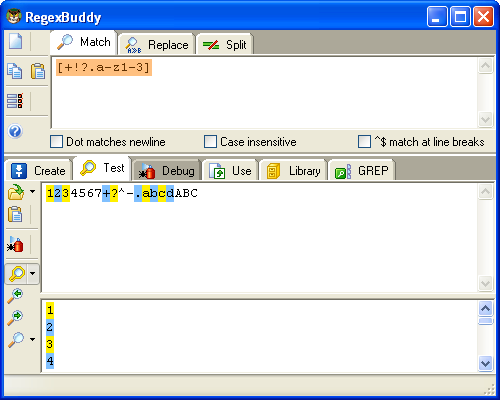
Notare che i soli caratteri speciali all'interno di un set di caratteri sono la chiusura della parentesi (]), il backslash (\), il caret (^) and il trattino (-). Gli altri metacaratteri rimangono normali caratteri all'interno del set, e non devono essere escaped (evasi) con il backslash (\). Per cercare un più (+) o un punto esclamativo (!), si utilizza "[+!]". La vostra regex comunque funzionerà regolarmente anche se specificato l'escape per ogni metacarattere, ma diminuirebbe la leggibilità della stessa "[\+\!]".
- ABBREVIAZIONI (SET DI CATATTERI)
Dato che spesso certi set di caratteri sono utilizzati spesso, sono disponibili una serie di abbreviazioni.
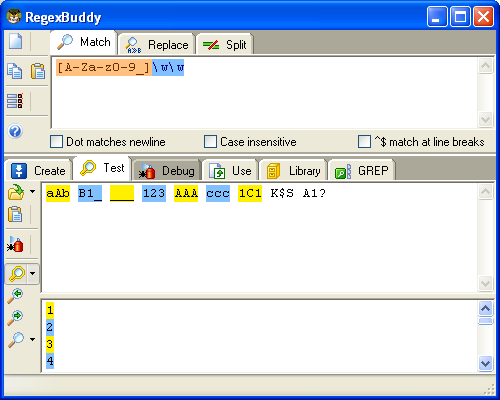
"\d" è l'abbreviazione di "[0-9]".
"\w" è l'abbreviazione di "[A-Za-z0-9_]".
"\s" contiene tutte le tipologie di spazio, ed il set di caratteri è formato da tutti quei caratteri "invisibili" (tab, ritorno a capo, spazio, ecc...). Esistono poi tutti i set anche per le singole tipologie di spazio. Per il tab "\t". Per il ritorno a capo "\n" e "\r". Si noti dunque che "\s", in realtà non è nient'altro che un set contenente altri set "[ \n\r\t]".
 - ABBREVIAZIONI (SET DI CATATTERI) NEGATE
- ABBREVIAZIONI (SET DI CATATTERI) NEGATE
La negazione delle abbreviazioni avviene semplicemente digitando l'abbreviazione stessa in maiuscolo. Ad esempio per fare il match di un carattere che non sia una cifra è sufficiente utilizzare "\D". Nota bene che, "[\D\S]" non è come scrivere "[^\d\s]". Nel primo caso si sta dicendo al motore regex di prendere o le non cifre o i non spazi, ma dato che gli spazi fanno parte delle non cifre e dato che le cifre fanno parte dei non spazi, l'insieme unito che ne risulta, è l'insieme di tutti i caratteri possibili, dunque la regex farà il match di un qualsiasi carattere. La seconda, invece, può solo fare il match di un carattere che non sia cifra, ne spazio, questo perchè si sta dicendo al motore regex, di rendere partecipe al match, soltanto i caratteri che non fanno parte dell'insieme delle cifre e degli spazi.
Stay Tuned!
