Eccomi di nuovo a scrivere sul mondo delle Regular Expression

, mi sono ritagliato un po' di tempo da questo stupendo MICROSOFT MVP SUMMIT 2008

, per scrivere di un importantissimo carattere che sicuramente sarà utilizzato tantissimo.
- IL PUNTO Prima di passare ad esaminare gli operatori "*?+" (come tutti già vorrebbero fare

),
abbiamo bisogno di attendere ancora alcuni post, per avere tutti gli
strumenti fondamentali per sfruttare al meglio quest'ultimi.
Nelle
regular expression, il punto è uno dei più comuni metacaratteri
utilizzati. Purtroppo è anche uno dei metacaratteri più abusato.
Il punto esegue il match di un
singolo carattere, senza preoccuparsi di che carattere esso sia. L'unica
eccezione è il carattere del ritorno a capo,
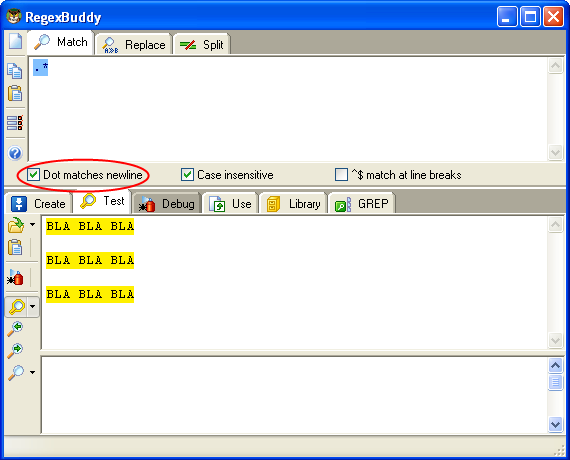
ma che nei moderni motori regex è possibile attivarne il matching,
abilitandone l'opportuno flag (Dot Matches newline (RegExBuddy) che per
.NET è il flag RegexOptions.Singleline).
RegexBuddy
C#
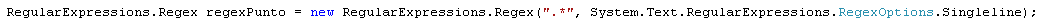
VB.NET
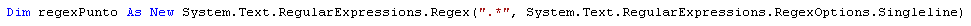
- IL PUNTO VA UTILIZZATO CON MODERAZIONE!
Il punto è davvero un potente nelle regex, perchè ci permette di essere
pigri, ma allo stesso tempo può creare grossi problemi, arrecandoci
altrettanta confusione. Può succedere infatti che a volte ci si ritrovi
con un matching completamente diverso da quello aspettato.
Vi
farò vedere questo con un semplice esempio. Mettiamo per esempio, che
volessimo matchare una data, ma vogliamo lasciare all'utente la libertà
di scegliere il separatore. Una prima e veloce soluzione sarebbe
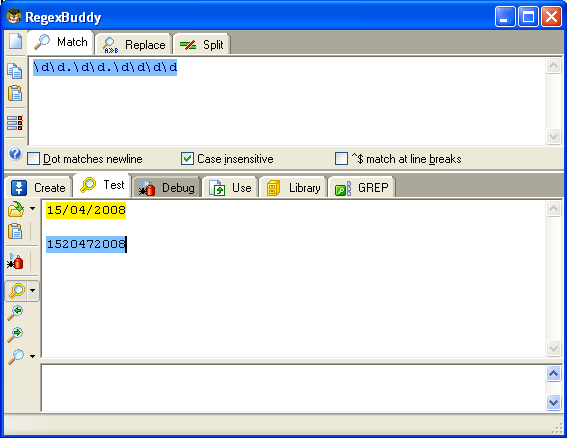
\d\d.\d\d.\d\d\d\d.
Sembrerebbe giusta ad una prima occhiata, prende correttamente date
come 15/04/2008. Il problema lo si ha però con 1520472008, che anche
esso verrebbe preso come una data valida, questo perchè il primo punto
prende il carattere '2' e il secondo il '7', perchè come si è detto
prima, il punto prende qualsiasi carattere, di conseguenza ovviamente
la regex del nostro esempio, non è logicamente corretta.
Una soluzione migliore potrebbe essere questa:
\d\d[- /.]\d\d[- /.]\d\d\d\d.
Questa regex prende come separatore valido la barra '/', lo spazio ' ',
il meno '-' e il punto '.'. Da ricordare che il punto non diventa un
metacarattere all'interno del set di caratteri, quindi non abbiamo
bisogno di farci l'escape con la barra '\'.
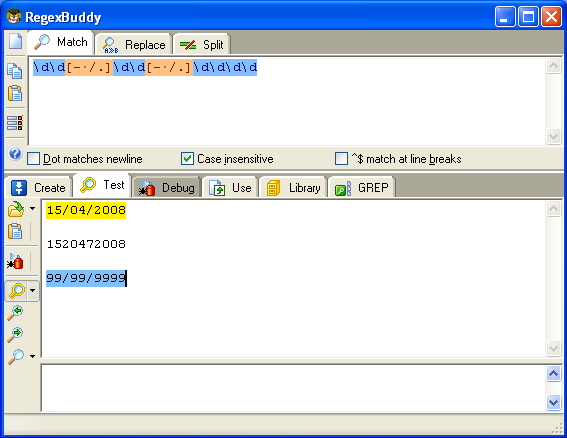
La suddetta regex è
ben lontana dalla perfezione, perchè prende come valide anche date come
99/99/9999. Uno step successivo potrebbe essere questo
[0-3]\d[- /.][0-1]\d[- /.]\d\d\d\d,
ma comunque continuerebbe ad accettare date come 39/19/99. La vostra
regex dovrà essere costruita quanto più perfetta, in base alle vostre
esigenze. Se ad esempio si sta validando un input utente, la regex
dovrà essere perfetta, mentre se si sta caricando un file dove la data
è pressoche sempre nella stessa sintassi, allora sarà sufficiente
applicare una regex che controlli solo la sintassi.
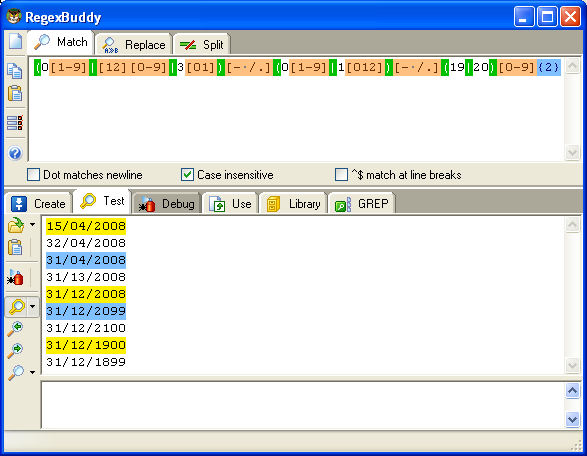
Una regular per validare una data in maniera piuttosto precisa, potrebbe essere la seguente:
(0[1-9]|[12][0-9]|3[01])[- /.](0[1-9]|1[012])[- /.](19|20)[0-9]{2} dove l'anno può variare da 1900 a 2099, come si può notare dall'esempio sottostante:
- UTILIZZARE SET DI CARATTERI NEGATI INVECE CHE IL PUNTO
Supponete
di volere prendere con la vostra regex una stringa con doppi apici agli
estremi. Ad una prima occhiata potrebbe sembrare facile, con una
semplice regex del tipo
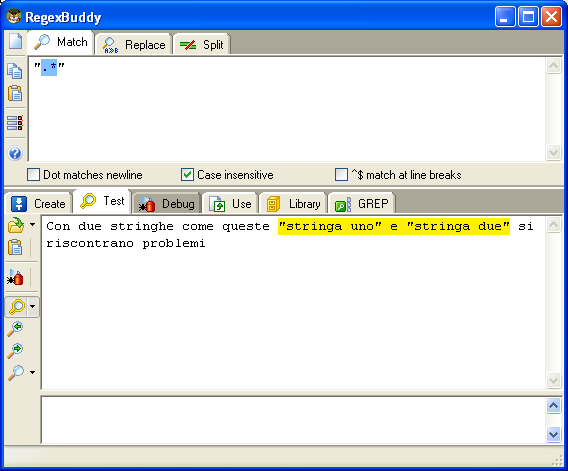
".*"
il nostro scopo sembra essere raggiunto bene. Il punto prende ogni
carattere, e l'asterisco permette al punto di ripetersi tutte le volte
necessarie, anche zero volte. Se proverete a testare la regex su
Mettere una "stringa" in mezzo a doppi apici, restituirà correttamente "stringa". Ora proviamo a testare la stessa regex su
Con due stringhe come queste "stringa uno" e "stringa due" si riscontrano problemi.
Qui la regex non fa più il suo dovere, o meglio, continua a farlo
benissimo, ma il risultato che ci aspettavamo non è quello restituito
cioè: "stringa uno" e "stringa due". Il perchè ha tutto questo lo si
trova nell'asterisco che è ingordo.
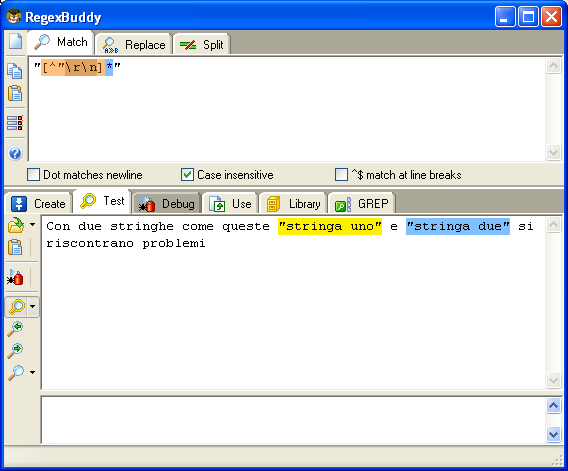
Come
per la regex della data, utilizzeremo anche qui i set di caratteri, per
correggere la nostra regex, però invece che utilizzare i normali set di
caratteri, utilizzeremo quelli negati. Ragionando in logica inversa, la
regex dovrà escludere tutti i doppi apici ed eventuali ritorni a capo,
e quindi la corretta regex risulta la seguente: "[^"\r\n]*"
L'uso
dei set di caratteri negati, verrà spiegato più dettagliatamente quando
presenterò gli operatori *+, ma è stato abbastanza importante da
doverlo menzionare subito anche qui.
Stay Tuned!
