Lo script transformation, può essere utilizzato in tre modi: come sorgente, come trasformazione e come destinazione. Questo permette tanta elasticità e tanta libertà di movimento nel caso in cui i task già presenti non soddisfino appieno le nostre esigenze. Nel caso in cui il task venga utilizzato come trasformazione (e quindi fra almeno una sorgente ed una ulteriore trasformazione/destinazione), è d'importanza fondamentale poter aggiungere metadati "lasciando passare" invariati quelli già presenti. Questa operazione, più comunemente chiamata pass through, non è sempre disponibile in automatico, e dipende da una importante proprietà che però cambia anche il comportamento del componente stesso. Il suo nome è SynchronousInputID. Ma vediamo nel dettaglio come procedere.Senza utilizzare editor avanzati, proviamo a creare un SSIS seguendo questi punti:- Creare un connection manager di tipo OLEDB (dal nome Utili nell'esempio), che si connetta ad un ipotetico database di utilità (nell'esempio ho un Utili in locale)- Creare un data flow e inserire al suo interno la seguente logica: La sorgente, legata al connection manager Utili interroga una semplicissima tabella così fatta:
La sorgente, legata al connection manager Utili interroga una semplicissima tabella così fatta:CREATE TABLE dbo.Utenti
(
IDUtente int NOT NULL
, Nome varchar(30) NOT NULL
, Cognome varchar(30) NOT NULL
, Eta tinyint NOT NULL
, CONSTRAINT PK_Utenti PRIMARY KEY CLUSTERED
(
IDUtente ASC
)
) ON [PRIMARY]
con i seguenti due record:
INSERT INTO dbo.Utenti
( IDUtente, Nome, Cognome, Eta )
VALUES
( 1, 'Alessandro', 'Alpi', 31 )
, ( 2, 'Michael', 'Denny', 27 )
GO
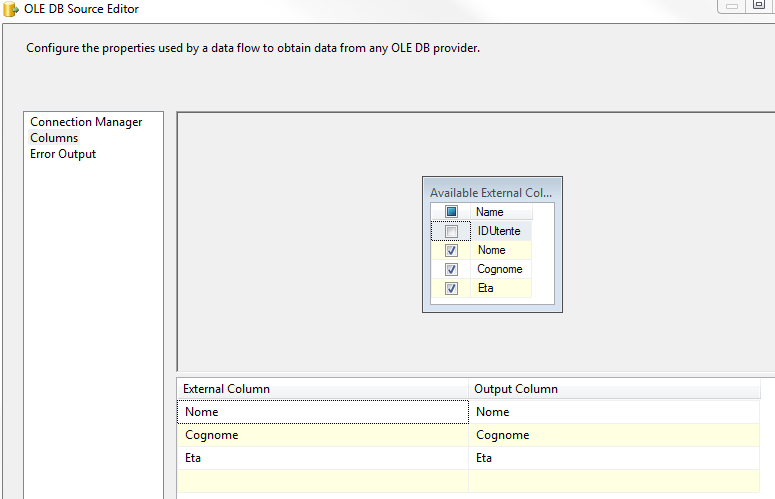
Come possiamo notare dalla seguente immagine, nella sorgente selezioniamo le tre colonne da considerare negli step successivi:
A questo punto, leghiamo lo script component.Esso, chiamato Variazione effettuerà una semplice concatenazione di stringhe. Quindi per esso verranno selezionate tutte le colonne che arrivano dalla sorgente, passate nello script e verrà generata una nuova colonna chiamataDescrizioneCompleta costruita come stringa "Nome: <nome e cognome> ; Età: <età>".
Di certo, una nuova colonna dovrà essere create, quindi andiamo ad aggiungerla nella definizione dello script component (sezione "input and output").
Per essere comodi, aggiungiamo un nuovo output con un nome più parlante (NuoveColonne) per agevolare lo sviluppo del codice. Questo è possibile tramite il tasto Add Output e tramite il property grid assegnato ad ogni oggetto su cui si fa focus.
Sotto ad esso andremo ad aggiungere una output column stavolta tramite il pulsante Add Column e rinomineremo la colonna, definendone anche il tipo:
Questa operazione rende potenzialmente disponibile un buffer di output all'interno dello script. Perchè potenzialmente? Perchè sarà proprio la proprietà definita all'inizio del post a determinare la creazione o meno di questo oggetto di uscita. Ad ogni modo però avremo l'accesso all'oggetto Row (parametro nella firma del metodo Input0_ProcessInputRow) per le colonne che arrivano dall'input.
La proprietà SynchronousInputID si trova, come si può notare nell'immagine dell'output NuoveColonne, nel property grid di un output creato nell'editor dello script e di default vale 0.
Ora possiamo dire che:
- se la SynchronousInputID vale 0 (None), l'output buffer è asincrono e quindi il metodo Input0_ProcessInputRow deve essere gestito con la creazione delle righe che l'utente vuole creare. Non solo, è necessario definire la collezione delle effettive colonne da passare all'uscita dello script component. Possono presentarsi due casi, assenza di output buffer o assenza di colonne di uscita. In ogni caso non è possibile legare ulteriori componenti dopo allo script (nel secondo caso è possibile ma non esistono componenti transformation che non accettino metadati di input). In poche parole se la proprietà vale 0 è necessario creare colonne di output, buffer e gestirli con il metodo di process delle righe di input. Nel nostro caso quindi avremo Row da gestire in sola lettura e NuoveColonneBuffer, automaticamente creato dall'engine, con le proprietà in output. Un esempio può essere il seguente:
public override void Input0_ProcessInputRow(Input0Buffer Row)
{
NuoveColonneBuffer.AddRow();
NuoveColonneBuffer.DescrizioneCompleta = String.Format("Nome: {0} {1}; Età: {2}", Row.Nome, Row.Cognome, Row.Eta);
}
- se la se la SynchronousInputID è impostata invece ad un input (nel nostro caso Input0 è il nome) allora l'output buffer è sincrono rispetto all'input. In questo caso nel metodo Input0_ProcessInputRow è sufficiente gestire il parametroRow, che ora è modificabile nelle sue proprietà (che corrispondono alle colonne). Nel nostro caso ecco l'esempio:
public override void Input0_ProcessInputRow(Input0Buffer Row)
{
Row.DescrizioneCompleta = String.Format("Nome: {0} {1}; Età: {2}", Row.Nome, Row.Cognome, Row.Eta);
}
A questo punto proviamo ad aggiungere un flat file destination e a collegare il nostro Variazione (considerando entrambi i casi sopra indicati).
Nel primo caso in output avremo SOLO la colonna creata, poichè non abbiamo aggiunto altre colonne all'output. E quindi al nostro flat file arriverà solo quella colonna o comunque quelle colonne aggiunte a mano all'output. Per passare l'intero column set dovremo quindi aggiungere tante colonne all'output quante sono quelle che devono passare al component successivo:
Nel secondo caso invece, anche se abbiamo aggiunto e gestito una sola colonna, avremo in output anche tutto il column set dell'input:
Attenzione però, abbiamo parlato di pass through delle colonne di input, ma la differenza tra synchronous e assynchronous pattern è ben diversa e non è la soluzione da seguire sempre. Ovviamente, proprio per come sono fatti, la scelta del tipo di script component da utilizzare varia in base agli scenari che ci si presentano. Uno script eseguito in maniera asincrona aspetta l'arrivo di tutto il resultset prima di processarlo, mentre in maniera sincrona processa riga per riga.
Dai books on line:
"A synchronous transformation processes incoming rows and passes them on in the data flow one row at a time. Output is synchronous with input, meaning that it occurs at the same time. Therefore, to process a given row, the transformation does not need information about other rows in the data set. In the actual implementation, rows are grouped into buffers as they pass from one component to the next, but these buffers are transparent to the user, and you can assume that each row is processed separately."
"You might decide that your design requires an asynchronous transformation when it is not possible to process each row independently of all other rows. In other words, you cannot pass each row along in the data flow as it is processed, but instead must output data asynchronously, or at a different time, than the input."
Per ulteriori informazioni sul pattern da seguire, leggete questo link.
Stay